當我們在談論Multi-Task Learning(多任務/多目標學習)
引言
Multi-Task Learning(MTL)即多任務學習,在一些領域也被稱為多目標學習。 MTL與常規單任務模型的區別在於,MTL僅使用一個模型就可以處理多個任務。比如在手機助手喚醒這個高頻場景,一般需要兩個模型,A模型用於檢測是否是手機用戶的語音,避免環境音或者自身迴聲干擾;B模型用於檢測用戶語音是否包含喚醒詞(如: Hey Siri、小愛同學等)。借助MTL,則可以在一個M模型中同時完成上述兩個任務,而事實上Iphone中Siri也正是這麼做的,詳見Apple官網。
MTL作為一種建模方式,既包含模型架構設計方面,也包含模型訓練過程方面。模型架構設計容易理解,即模型需要支持多種任務的輸入輸出,需要使多任務之間訊息更有效率地共享等;而在模型訓練過程方面,需要包含多任務的數據集劃分,損失函數的定義,訓練流程等方面。從這個角度看,目前中文社區中大部分MTL介紹的文章是“有偏”的,對於部分論文或者技巧的解析深度有餘,而對MTL的系統介紹遠遠不足。以至於在推薦系統領域,部分同學會誤解MTL就是MMoE、ESMM。
因此,本文旨在較為系統的介紹MTL的基礎,使讀者能相對“無偏”了解這個領域,以便正確地借鑒其他論文中的知識和技巧。限於本人知識和時間有限,文章如果有疏漏或者錯誤,歡迎指正:)
Multi-Task Learning簡介
很難想像,MTL的神經網絡是早在1993年已經提出的概念,來自於Caruana的“Multitask Learning: A Knowledge-Based Source of Inductive Bias”。其單任務模型(Fig1)和MTL模型結構(Fig2)如下,對於MTL模型,神經網絡有多個輸出的節點,每個節點對應一個任務,可以說是非常符合直覺的。


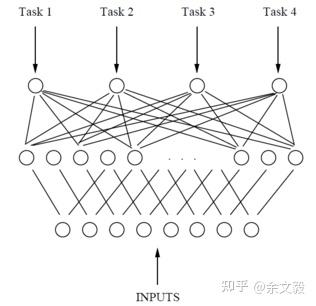
那麼就先以這個最簡單的MTL模型,談談除了模型比較Fancy之外,出於哪些更實際的理由促使大家使用MTL而多個非單任務模型呢?從實用角度來說,有以下幾點:
第一,MTL可以在模型效果不下降的情況下提升多任務預測效率。由於可以共享一部分網絡結構,MTL的總網絡參數量相較於N個單任務網絡參數量總和顯著降低,這意味著在實時多任務預測場景下MTL模型效率會更高;同時對某個任務而言,MTL模型參數(共享參數+任務獨立參數)與單任務模型參數量一樣,所以其模型理論表達能力並沒有降低。
第二,MTL對於相關的多任務,可以提升小樣本任務訓練效果。得益於MTL的參數共享機制,共享參數可以通過樣本充足的任務得到充分訓練,減少小樣本任務單獨訓練不充分,容易過擬合的問題。
第三,MTL通過引入Inductive Bias,可以提升所有相關任務的魯棒性。在機器學習中,無時無刻都在對問題做一些假設(或者叫先驗、約束),這些就被稱為Inductive Bias,如L1正則是模型稀疏性的假設、CNN 是特徵局部性的假設、RNN是樣本時序性的假設……對於MTL,Inductive Bias則是不同任務之間效果的約束,如果這些約束合理,那麼顯然會讓所有任務都更不容易受噪聲樣本影響,從而提升模型的魯棒性。
上面幾點優勢本質上都是因為“共享參數”帶來的。因此,如果不同任務之間差異巨大,根本沒什麼需要共享的,“共享參數”機制就會使Inductive Bias從約束變成噪聲,拉低每一個任務的效果。
有時候即使沒有同時訓練多個任務的需求,但是出於對上述優勢的考慮,會額外引入一些輔助任務構造成MTL的模型,輔助將主任務訓練的更加魯棒。
Multi-Task Learning與其他學習方式
上面對MTL進行了簡單介紹,其中關於“參數共享”部分很容易讓人想起遷移學習,而多輸出節點部分則很像多分類。關於他們之間的關係,Wasi Ahmad的《Multi-Task Machine Learning》中比較合理地歸納,如下圖。

遷移學習(Transfer Learning):將A領域的知識應用到B領域中,從而緩解B領域樣本不足的問題。在圖像領域,最常見的遷移學習之一就是複用Pretrain的模型用於圖像特徵提取,曾經紅極一時的VGG16、Inception-v3等都是論文常客。在NLP領域,當紅的Bert模型+Finetune的訓練形式也已經是標配。
多任務學習(Multi-Task Learning):同時對多個任務建模,通過對多個任務之間的參數相關性添加約束(如“參數共享”)將所有任務聯繫起來。在推薦系統領域,Google的MMoE和阿里巴巴的ESMM是較為人熟知的MTL模型。
多標籤學習(Multi-Label Learning):即多標籤多分類學習,對一個樣本同時預測多個標籤。如對每個人興趣愛好的預測,總興趣標籤空間可以包含動漫、音樂、攝影、交友等等,某個人的興趣為總空間的子集,訓練和預測的目標即為這個子集所表示成的Multi Hot向量。
多類別學習(Multi-Class Learning):即單標籤多分類學習,對一個樣本同時預測多個分類的概率。如語言分類任務中,需要預測某個文本是漢語、英語、阿拉伯語等等,訓練和預測目標為這種語言所表示成的One Hot 向量。
接下來,我們開始具體介紹MTL。
Multi-Task Learning定義
首先,需要對“任務”這個概念有個明確的定義(這裡參考亞利桑那大學博士論文《MULTI-TASK AND TRANSFER LEARNING IN LOW-RESOURCE SPEECH RECOGNITION》),一個任務定義如下:
- 源數據:X 表示某領域的樣本集合
- 目標數據:Y 表示某領域的目標集合
- 映射:f: X → Y,表示從源到目標的轉換關係
對於一個MTL模型,能夠同時對多個上述任務進行建模。模型中部分參數是所有任務共享的,下面稱為“共享參數”;另外一部分參數是每個任務獨享的,下面稱為“獨立參數”。那麼理想情況下,我們希望“共享參數”在所有樣本計算Loss後更新,而“獨立參數”只在對應任務樣本計算Loss後才更新,這就達到了一起訓練的目的。
有了上面的定義,就可以對MTL的主要形式做出預判,大概會有以下三種形式。
第一,給定一個源數據集(X),以及多個目標數據集(Y1,Y2,...Yn),MTL將X分別映射到每個目標數據集中,如圖Fig4(a)。這也是最普遍的MTL形式,下面把這種形式稱為Single Input Multi Output(SIMO)。
第二,給定多個源數據集(X1,X2...Xn),以及多個目標數據集(Y1,Y2,...Yn),MTL分別將Xi映射到Yi,如圖Fig4(c )。這種形式不如第一種常見,卻是大部分場景下,最容易將單任務快速遷移到MTL進行嘗試的方式。下面把這種形式稱為Multi Input Multi Output(MIMO)。
第三,給定多個源數據集(X1,X2...Xn),以及一個目標數據集(Y),MTL分別將Xi映射到目標Y,如圖Fig4(b)。如果這裡Y被定義為所有源數據集的目標的超集,這個MTL任務就退化成上面提到的Multi-Label Learning任務。這種形式一般不被當成是MTL,所以談論MTL時最不常見。下面把這種形式稱為Multi Input Single Output(MISO)。
需要強調的是,這裡所說的“MTL的形式”,指的是如何組合不同任務的數據,而不是僅僅指網絡結構。舉個例子,對於Multi Input Multi Output形式的MTL模型,每個任務的源數據集不同,但如果Multi Input的特徵完全一致,大可以共享特徵解析部分的網絡參數。

下面,針對Single Input Multi Output、Multi Input Multi Output 兩種常見的MTL形式進行具體介紹。其中主要包含兩點:模型結構,模型訓練(Loss定義,訓練步驟等)。這裡僅會以部分領域較為知名的基礎模型為例,意在直觀的理解上述兩點,對更深入細節有興趣的同學可以閱讀給出的參考文獻。
Single Input Multi Output 模型
SIMO形式的MTL模型比較常見,這裡舉計算機視覺、推薦系統中的兩個例子。
計算機視覺
在計算機視覺領域,2014年香港中文大學的“Facial Landmark Detection by Deep Multi-task Learning”是一篇將多任務用於人臉關鍵點檢測的文章,提出了TCDCN模型。人臉關鍵點包括人臉輪廓、眼睛、眉毛、嘴唇以及鼻子等等。
其模型結構如Fig6所示,可以看出有多個輸出:一個主任務Landmark Detection,和其他輔助任務。輔助任務用於幫助主任務學習CNN的網絡參數,文中的輔助任務包括:性別、是否帶眼鏡、是否微笑、臉部的姿勢等。為了直觀的說明每個任務,Fig5展示了訓練樣本,包含圖像即每個任務的Label訊息。
TCDCN模型的損失函數也非常符合直覺,如Fig7所示。其中第一項就是Landmark Detection的損失函數;而第二項就是輔助任務的損失函數,第二項λ是輔助任務Loss的權重,用於調節輔助任務的重要性。



推薦系統
在推薦系統領域,2018年來自阿里巴巴的“Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate”是一篇將多任務用於點擊率、轉化率預估的文章,提出的模型稱為ESMM。這裡稍微解釋下各個指標的含義:
商品點擊率(CTR,pCTR)= 點擊數/曝光數,衡量用戶看到一個鏈接後點擊的概率。
商品轉化率(CVR,pCVR)= 轉化數/點擊數,衡量用戶點擊商品詳情后,下單購買的概率。
商品點擊轉化率(CTCVR,pCTCVR)= 點擊率*轉化率。
ESMM模型結構如Fig8所示,包含一個主任務CVR預估,以及輔助任務CTCVR預估。 CTCVR任務同樣是用於幫助CVR把Eembedding Lookup Table學習的更好,避免CVR預估由於樣本偏少導致容易過擬合泛化性差等問題。
ESMM的損失函數如Fig9所示,這裡主任務CVR預估並沒有單獨計算Loss。可以看出最終損失是CTR、CTCVR的損失之和,主任務CVR體現在CTCVR這一項中,這避免了部分用戶沒有點擊導致無法計算CVR的問題,是非常優秀的轉換。


模型訓練
從上面可以看出,Single Input Multi Output 模型的Loss一般都會有多項,每一項對應一個任務(或者該任務的某種轉換任務)。所以每個batch訓練比較簡單,直接更新整個網絡的參數即可。
但是Loss相加也會帶來一個問題,不同任務的目標不同,可能是回歸也可能是分類,那Loss的尺度就不一樣。如Fig7中的λ,就是用於調節不同任務的Loss大小,避免某個任務Loss太大,其他任務無法參與訓練。這就引入一個很麻煩的問題,λ要怎麼調節才能平衡每個任務呢?
最簡單當然是根據專家知識調參,也有一些工作提供了自動調節Loss尺度的方案,如“Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics”,這裡就不再展開。
Multi Input Multi Output 模型
MIMO形式的MTL模型不那麼常見(可能是因為看起來沒啥技術含量不好灌水?),這裡僅舉一個相對知名的自然語言處理的例子。 (如果有同學知道更多MIMO的例子,歡迎留言區補充,最好有文章標題,方便其他同學學習)
自然語言處理
在自然語言處理領域,2019年來自微軟的“Multi-Task Deep Neural Networks for Natural Language Understanding”是一篇將MTL用於學習Text Representation的文章,提出的模型稱為MTDNN。 MTDNN在10個NLP任務中刷新了記錄,並在文章中多次強調其取得了比BERT更好的Representation結果(這種高強度的CUE總讓人有一種相愛相殺的感覺哈哈)。
MTDNN的模型結構如Fig10所示。雖然涉及較多領域知識,但其實圖中Shared Layers的具體含義不明白細節,也能看出整體結構就類似於Fig2中最原始的MTL模型。 MTDNN不是單一的主任務,而是所有任務一樣重要,其任務包括:句子情感分類、文本相似性回歸、文本相似性分類、文本相似性排序等等。
MTDNN的訓練方式也很直觀,如Fig11所示。其中包含兩個步驟:
第一步,Pretrain Encoder Layers。這一步類似BERT,利用無監督任務將Encoder Layers的海量參數學好,這裡的無監督任務包含Masked Language Modeling 和Next Sentence Prediction。這一步可以理解成學習模型的“共享參數”。
第二步,MTL學習每個任務。這一步就是利用多任務的標籤來精調模型(“共享參數”和“獨立參數”都會參與訓練),做法也很簡單,就是每個batch抽取一個任務的樣本,然後根據該任務的損失函數進行模型參數更新。由於不同任務的損失函數不耦合,就不需要考慮Loss尺度的問題。


Multi-Task Learning 參數共享形式
Hard / Soft Parameter Sharing

MTL模型中參數共享的方式一般說來有兩種,分別是Hard Parameter Sharing和Soft Parameter Sharing。
Hard Parameter Sharing即Fig12(左),表示對多任務直接共享部分神經網絡參數,是最主流的參數共享形式。上面提到的例子也基本都是這種形式,適用於多任務之間相關性比較強的場景。
Soft Parameter Sharing即Fig12(右),表示每個任務分別有自己的神經網絡參數,但是會對多任務的網絡參數之間加約束,使參數彼此相似。這種方式實際中不太常見,可用於多任務之間相關性比較弱的場景。約束指標如L2 Norm(見“Low Resource Dependency Parsing: Cross-lingual Parameter Sharing in a Neural Network Parser”)、Trace Norm(見“Trace Norm Regularised Deep Multi-Task Learning”)。
Mixture of Experts


上面提到Soft Parameter Sharing可用於多任務之間相關性較較弱的場景,但是如果多任務之間相關性非常低,一般也不會考慮使用MTL。更常見的是,多任務之前有較為相關的部分,也有相互獨立的部分,直接Hard Parameter Sharing也不太合適,Mixture of Experts模型就適合這種場景。
Google在2018年“Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts”文章提出Multi-Mixture-of-Experts(MMoE)模型,是對Geoffrey Hinton 提出的Mixture-of-Experts(MoE 、One-gate MoE)的一種改進,而它們都是一種特殊的Hard Parameter Sharing模型。這三種模型結構如Fig13,其中(a)Hard Parameter Sharing模型,(b)MoE模型,(c)MMoE模型。
MoE模型將“共享參數”劃分為N個Expert子網絡,而Gate網絡負責輸出N個Expert子網絡的權重,最終結果是Expert子網絡與Gate的加權和。思想上其實類似於後來的Attenton。
MMoE則是在MoE的基礎上,對每一個任務有獨自的Gate網絡負責輸出權重,使不同的任務能更多樣化地使用Expert網絡。其具體公式如Fig14,也比較好理解,就不再贅述。
尾巴
本文旨在較為全面的介紹MTL的基礎知識,包括MTL與其他機器學習算法的關係,MTL的主要建模形式、訓練方式,以及關於參數共享的擴展形式。雖然對每個話題都只進行了基本介紹,文章也已經快超6000字,所以文中對每一項更深入的話題沒有進一步擴展,只留了一些參考文獻供有興趣的同學自行學習。
有其他疑問的同學歡迎關注公眾號“”私信交流,或者評論區留言交流,我會在精力範圍內盡量回复。
最後祝大家Happy牛Year!
Reference
https:// ruder.io/multi-task/ind ex.html#hardparametersharing
其他參考文獻已經在文中對應部分給出。
最後,歡迎關注公眾號(當我們在談論這些那些),後續文章也會同步發佈在上面~