Sidetable:一種高效的Python 數據框處理工具!
歡迎關注
我們知道Pandas 是數據科學社區中流行的Python 包,它包含許多函數和方法來分析數據。儘管它的功能對於數據分析來說足夠有效,但定制的庫可以為Pandas 處理數據帶來非常棒的體驗。
Sidetable 就是一個開源Python 庫,它是一種可用於數據分析和探索的工具,作為value_counts 和crosstab 的功能組合使用的。在本文中,我們將更多地討論和探索其功能。歡迎收藏學習、點贊支持。
更多內容,可參考鏈接:
安裝
可以使用從PyPI 安裝Sidetable
pip install sidetable用法
我們將使用從Kaggle 下載的Titanic 數據集來實現該庫。
sidetable 的思想是減少數據分析所需的代碼行數並加快工作流程。對於任何數據集,都需要執行一些數據分析任務,包括可視化特徵分佈、頻率計數、缺失記錄計數。
我們將使用Titanic 數據集詳細討論Sidetable 庫的特性。
1、freq()
Pandas 提供了value_counts() 函數,用於計算特徵的頻率計數。 Pandas 可以計算分佈計數和概率分佈,但你可能希望更容易組合這些值。
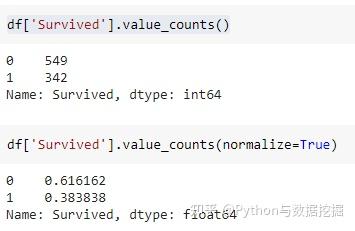
分佈計數和概率分佈可以結合使用,但需要大量的輸入和代碼記憶。
對於sidetable,使用freq() 函數在一行Python代碼中實現它更簡單。你可以獲得累計總數、百分比和更大的靈活性。


除此之外,還可以對多個列進行分組,以可視化已分組要素的分佈。

你還可以使用參數value 指定要素列,以指示分組的數據“sum”應基於特定列。

2、Counts()
sidetable 中的counts() 函數可以生成一個匯總表,該匯總表可用於確定你需要考慮為分類或數值的特徵,以便進一步分析和建模。 counts() 函數顯示特徵的唯一值的數量以及最頻繁和最不頻繁的值。

可以使用exclude 和include 參數從數據集中排除或包含特定數據類型。
3、missing()
sidetable 中missing()函數生成一個匯總表,該匯總表按每列的總缺失值的計數和百分比顯示缺失記錄。
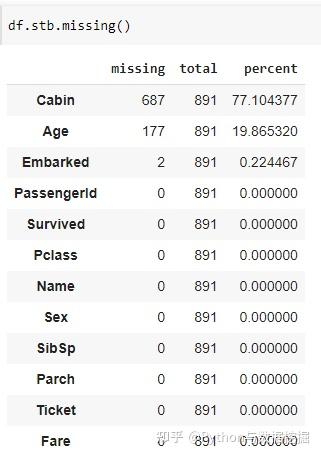
4、subtotal()
Sidetable 中subtotal() 函數最適合與Pandas 中的group by 函數一起使用。它可用於計算數據幀分組的一個或多個級別的小計。

subtotal()函數可以將其添加到分組數據的一個或多個級別。你需要首先使用groupby()函數對數據框進行分組,然後在每個級別添加一個小計。

結論
Sidetable 是一種高效且方便的工具,它結合了Pandas 的value_counts 和crosstab,生成一個可解釋且易於理解的匯總表,還可用於提供分析結果。語法的簡單性使其成為用於數據分析和探索的更好的庫。
文章推薦
Rich:Python開發者的完美終端工具!
再次出發! FaceBook 開源"一站式服務"時序利器Kats !
Pandas pipe: 一種更優雅的數據預處理方法!
有了這個可視化插件, Python 編程更輕鬆!
超硬核!分享9個功能強大卻鮮為人知的Python 工具包!
這個算法讓我無法拒絕!特徵篩選瑰寶Boruta 真棒!
【建議收藏】必知必會! Python 中最流行的十個標準庫!
4 款Python 數據探索性分析(EDA)工具包,總有一款適合你
時間序列預測的7種Python工具包,總有一款適合你!
超級乾貨!史上最全數據分析學習路線(附資源下載)
整理不易,有所收穫,點個贊和愛心