
這40個Python可視化圖表案例,強烈建議收藏!
大家好,我是小F~
數據可視化是數據科學中關鍵的一步。
在以圖形方式表現某些數據時,Python能夠提供很大的幫助。
不過有些小伙伴也會遇到不少問題,比如選擇何種圖表,以及如何製作,代碼如何編寫,這些都是問題!
今天給大家介紹一個Python圖表大全,40個種類,總計約400個範例圖表。
分為7個大系列,分佈、關係、排行、局部整體、時間序列、地理空間、流程。
文檔地址
https://www.
GitHub地址
https://
給大家提供了範例及代碼,幾分鐘內就能構建一個你所需要的圖表。
下面就給大家介紹一下~
01. 小提琴圖
小提琴圖可以將一組或多組數據的數值變量分佈可視化。
相比有時會隱藏數據特徵的箱形圖相比,小提琴圖值得更多關注。
import seaborn as sns import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.violinplot(x=df["species"], y=df["sepal_length"]) plt.show() import matplotlib.pyplot as plt import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.violinplot(x=df["species"], y=df["sepal_length"]) plt.show() # 加載數據df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.violinplot(x=df["species"], y=df["sepal_length"]) plt.show() # 繪圖顯示sns.violinplot(x=df["species"], y=df["sepal_length"]) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.violinplot(x=df["species"], y=df["sepal_length"]) plt.show()使用Seaborn的violinplot()進行繪製,結果如下。

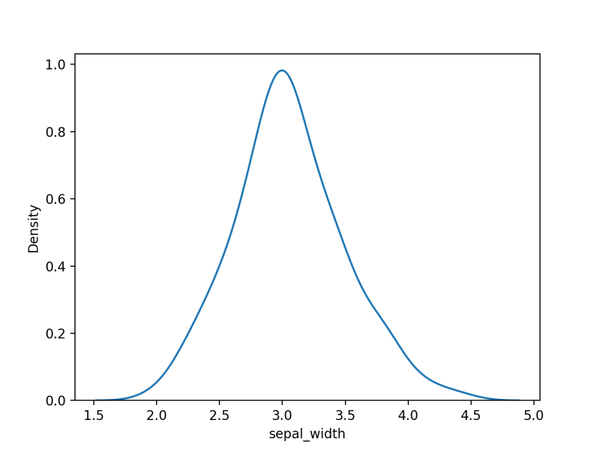
02. 核密度估計圖
核密度估計圖其實是對直方圖的一個自然拓展。
可以可視化一個或多個組的數值變量的分佈,非常適合大型數據集。
import seaborn as sns import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.kdeplot(df['sepal_width']) plt.show() import matplotlib.pyplot as plt import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.kdeplot(df['sepal_width']) plt.show() # 加載數據df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.kdeplot(df['sepal_width']) plt.show() # 繪圖顯示sns.kdeplot(df['sepal_width']) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.kdeplot(df['sepal_width']) plt.show()使用Seaborn的kdeplot()進行繪製,結果如下。
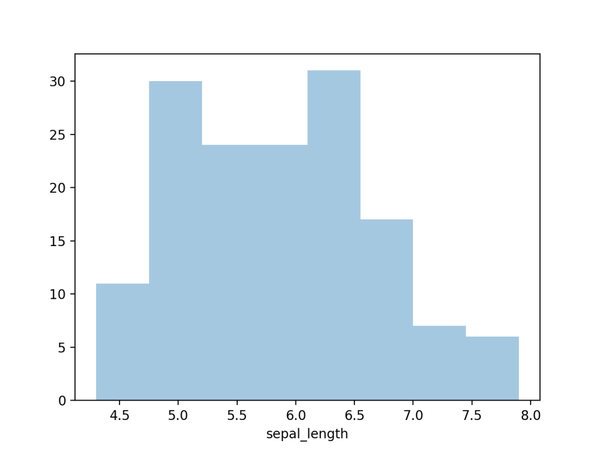
03. 直方圖
直方圖,可視化一組或多組數據的分佈情況。
import seaborn as sns import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.distplot(a=df["sepal_length"], hist=True, kde=False, rug=False) plt.show() import matplotlib.pyplot as plt import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.distplot(a=df["sepal_length"], hist=True, kde=False, rug=False) plt.show() # 加載數據df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.distplot(a=df["sepal_length"], hist=True, kde=False, rug=False) plt.show() # 繪圖顯示sns.distplot(a=df["sepal_length"], hist=True, kde=False, rug=False) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.distplot(a=df["sepal_length"], hist=True, kde=False, rug=False) plt.show()使用Seaborn的distplot()進行繪製,結果如下。
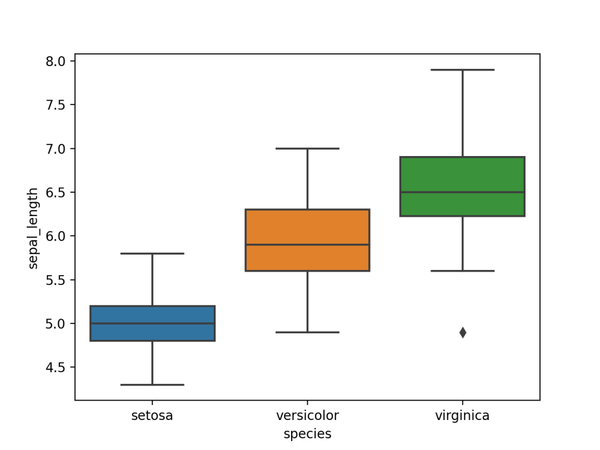
04. 箱形圖
箱形圖,可視化一組或多組數據的分佈情況。
可以快速獲得中位數、四分位數和異常值,但也隱藏數據集的各個數據點。
import seaborn as sns import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.boxplot(x=df["species"], y=df["sepal_length"]) plt.show() import matplotlib.pyplot as plt import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.boxplot(x=df["species"], y=df["sepal_length"]) plt.show() # 加載數據df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.boxplot(x=df["species"], y=df["sepal_length"]) plt.show() # 繪圖顯示sns.boxplot(x=df["species"], y=df["sepal_length"]) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.boxplot(x=df["species"], y=df["sepal_length"]) plt.show()使用Seaborn的boxplot()進行繪製,結果如下。
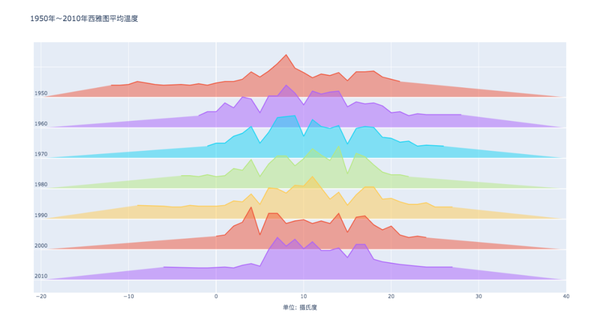
05. 山脊線圖
山脊線圖,總結幾組數據的分佈情況。
每個組都表示為一個密度圖,每個密度圖相互重疊以更有效地利用空間。
import plotly.graph_objects as go import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() import numpy as np import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() import pandas as pd import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 讀取數據temp = pd.read_csv('2016-weather-data-seattle.csv') import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 數據處理, 時間格式轉換temp['year'] = pd.to_datetime(temp['Date']).dt.year import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 選擇幾年的數據展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() temp = temp[temp['year'].isin(year_list)] import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 繪製每年的直方圖,以年和平均溫度分組,並使用'count'函數進行匯總temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 使用Plotly繪製脊線圖,每個軌跡對應於特定年份的溫度分佈# 將每年的數據(溫度和它們各自的計數)存儲在單獨的數組,並將其存儲在字典中以方便檢索array_dict = {} import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() for year in year_list: import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 每年平均溫度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 每年溫度計數array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 創建一個圖像對象fig = go.Figure() import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() for index, year in enumerate(year_list): import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 使用add_trace()繪製軌跡fig.add_trace(go.Scatter( import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() x=[-20, 40], y=np.full(2, len(year_list) - index), import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() mode='lines', import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() line_color='white')) import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() fig.add_trace(go.Scatter( import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() x=array_dict[f'x_{year}'], import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() fill='tonexty', import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() name=f'{year}')) import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 添加文本fig.add_annotation( import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() x=-20, import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() y=len(year_list) - index, import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() text=f'{year}', import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() showarrow=False, import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() yshift=10) import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() # 添加標題、圖例、xy軸參數fig.update_layout( import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() title='1950年~2010年西雅圖平均溫度', import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() showlegend=False, import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() xaxis=dict(title='單位: 攝氏度'), import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() yaxis=dict(showticklabels=False) import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show() ) import plotly.graph_objects as go import numpy as np import pandas as pd # 读取数据temp = pd.read_csv('2016-weather-data-seattle.csv') # 数据处理, 时间格式转换temp['year'] = pd.to_datetime(temp['Date']).dt.year # 选择几年的数据展示即可year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010] temp = temp[temp['year'].isin(year_list)] # 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index() # 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索array_dict = {} for year in year_list: # 每年平均温度array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC'] # 每年温度计数array_dict[f'y_{year}'] = temp[temp['year'] == year]['count'] array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) / (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min()) # 创建一个图像对象fig = go.Figure() for index, year in enumerate(year_list): # 使用add_trace()绘制轨迹fig.add_trace(go.Scatter( x=[-20, 40], y=np.full(2, len(year_list) - index), mode='lines', line_color='white')) fig.add_trace(go.Scatter( x=array_dict[f'x_{year}'], y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4, fill='tonexty', name=f'{year}')) # 添加文本fig.add_annotation( x=-20, y=len(year_list) - index, text=f'{year}', showarrow=False, yshift=10) # 添加标题、图例、xy轴参数fig.update_layout( title='1950年~2010年西雅图平均温度', showlegend=False, xaxis=dict(title='单位: 摄氏度'), yaxis=dict(showticklabels=False) ) # 跳转网页显示fig.show()Seaborn沒有專門的函數來繪製山脊線圖,可以多次調用kdeplot()來製作。
結果如下。
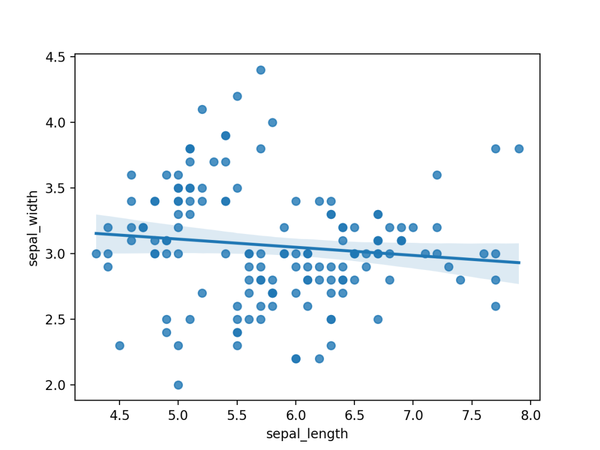
06. 散點圖
散點圖,顯示2個數值變量之間的關係。
import seaborn as sns import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.regplot(x=df["sepal_length"], y=df["sepal_width"]) plt.show() import matplotlib.pyplot as plt import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.regplot(x=df["sepal_length"], y=df["sepal_width"]) plt.show() # 加載數據df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.regplot(x=df["sepal_length"], y=df["sepal_width"]) plt.show() # 繪圖顯示sns.regplot(x=df["sepal_length"], y=df["sepal_width"]) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.regplot(x=df["sepal_length"], y=df["sepal_width"]) plt.show()使用Seaborn的regplot()進行繪製,結果如下。
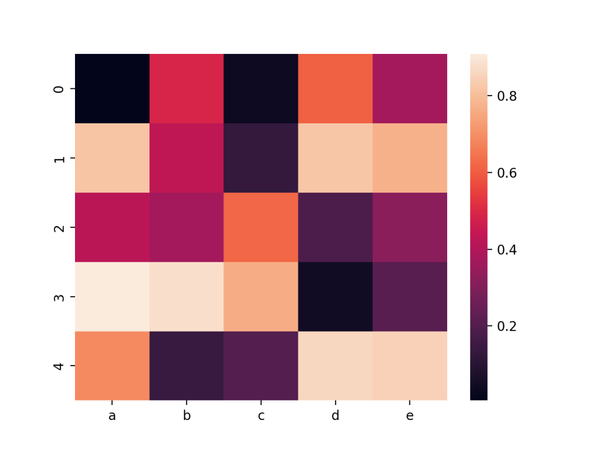
07. 矩形熱力圖
矩形熱力圖,矩陣中的每個值都被表示為一個顏色數據。
import seaborn as sns import seaborn as sns import pandas as pd import numpy as np # Create a dataset df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) # Default heatmap p1 = sns.heatmap(df) import pandas as pd import seaborn as sns import pandas as pd import numpy as np # Create a dataset df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) # Default heatmap p1 = sns.heatmap(df) import numpy as np import seaborn as sns import pandas as pd import numpy as np # Create a dataset df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) # Default heatmap p1 = sns.heatmap(df) # Create a dataset import seaborn as sns import pandas as pd import numpy as np # Create a dataset df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) # Default heatmap p1 = sns.heatmap(df) df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) import seaborn as sns import pandas as pd import numpy as np # Create a dataset df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) # Default heatmap p1 = sns.heatmap(df) # Default heatmap import seaborn as sns import pandas as pd import numpy as np # Create a dataset df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"]) # Default heatmap p1 = sns.heatmap(df)使用Seaborn的heatmap()進行繪製,結果如下。
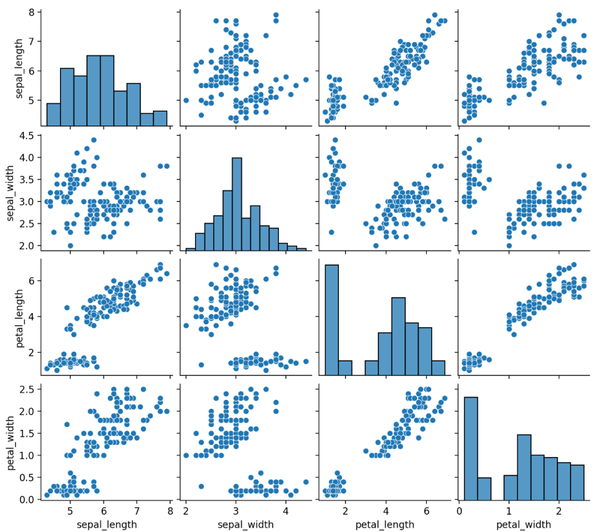
08. 相關性圖
相關性圖或相關矩陣圖,分析每對數據變量之間的關係。
相關性可視化為散點圖,對角線用直方圖或密度圖表示每個變量的分佈。
import seaborn as sns import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.pairplot(df) plt.show() import matplotlib.pyplot as plt import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.pairplot(df) plt.show() # 加載數據df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.pairplot(df) plt.show() # 繪圖顯示sns.pairplot(df) import seaborn as sns import matplotlib.pyplot as plt # 加载数据df = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 绘图显示sns.pairplot(df) plt.show()使用Seaborn的pairplot()進行繪製,結果如下。
09. 氣泡圖
氣泡圖其實就是一個散點圖,其中圓圈大小被映射到第三數值變量的值。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt import seaborn as sns from gapminder import gapminder # 导入数据data = gapminder.loc[gapminder.year == 2007] # 使用scatterplot创建气泡图sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000)) # 显示plt.show() import seaborn as sns import matplotlib.pyplot as plt import seaborn as sns from gapminder import gapminder # 导入数据data = gapminder.loc[gapminder.year == 2007] # 使用scatterplot创建气泡图sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000)) # 显示plt.show() from gapminder import gapminder import matplotlib.pyplot as plt import seaborn as sns from gapminder import gapminder # 导入数据data = gapminder.loc[gapminder.year == 2007] # 使用scatterplot创建气泡图sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000)) # 显示plt.show() # 導入數據data = gapminder.loc[gapminder.year == 2007] import matplotlib.pyplot as plt import seaborn as sns from gapminder import gapminder # 导入数据data = gapminder.loc[gapminder.year == 2007] # 使用scatterplot创建气泡图sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000)) # 显示plt.show() # 使用scatterplot創建氣泡圖sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000)) import matplotlib.pyplot as plt import seaborn as sns from gapminder import gapminder # 导入数据data = gapminder.loc[gapminder.year == 2007] # 使用scatterplot创建气泡图sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000)) # 显示plt.show()使用Seaborn的scatterplot()進行繪製,結果如下。
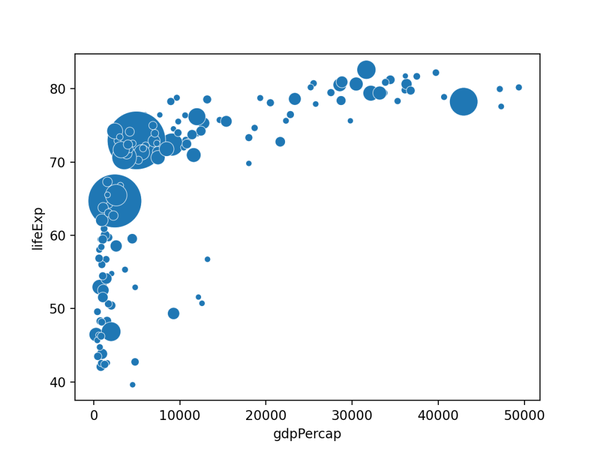
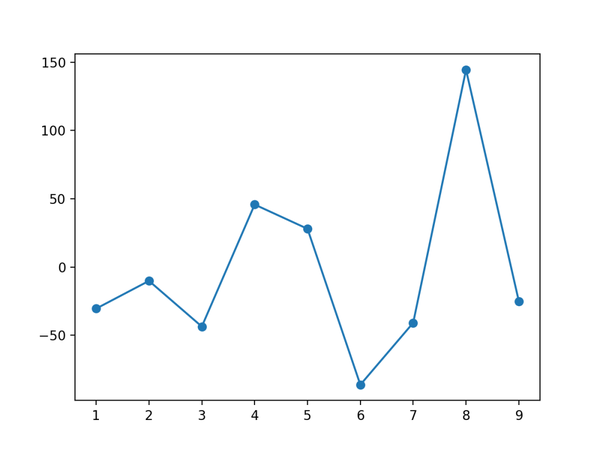
10. 連接散點圖
連接散點圖就是一個線圖,其中每個數據點由圓形或任何類型的標記展示。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt import numpy as np import pandas as pd # 创建数据df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)}) # 绘制显示plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o') plt.show() import numpy as np import matplotlib.pyplot as plt import numpy as np import pandas as pd # 创建数据df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)}) # 绘制显示plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o') plt.show() import pandas as pd import matplotlib.pyplot as plt import numpy as np import pandas as pd # 创建数据df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)}) # 绘制显示plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o') plt.show() # 創建數據df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)}) import matplotlib.pyplot as plt import numpy as np import pandas as pd # 创建数据df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)}) # 绘制显示plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o') plt.show() # 繪製顯示plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o') import matplotlib.pyplot as plt import numpy as np import pandas as pd # 创建数据df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)}) # 绘制显示plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o') plt.show()使用Matplotlib的plot()進行繪製,結果如下。
11. 二維密度圖
二維密度圖或二維直方圖,可視化兩個定量變量的組合分佈。
它們總是在X軸上表示一個變量,另一個在Y軸上,就像散點圖。
然後計算二維空間特定區域內的次數,並用顏色漸變表示。
形狀變化:六邊形a hexbin chart,正方形a 2d histogram,核密度2d density plots或contour plots。
import numpy as np import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() import matplotlib.pyplot as plt import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() from scipy.stats import kde import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 創建數據, 200個點data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() x, y = data.T import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 創建畫布, 6個子圖fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 第一個子圖, 散點圖axes[0].set_title('Scatterplot') import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[0].plot(x, y, 'ko') import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 第二個子圖, 六邊形nbins = 20 import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[1].set_title('Hexbin') import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 2D 直方圖axes[2].set_title('2D Histogram') import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 高斯kde import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() k = kde.gaussian_kde(data.T) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() zi = k(np.vstack([xi.flatten(), yi.flatten()])) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 密度圖axes[3].set_title('Calculate Gaussian KDE') import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 添加陰影axes[4].set_title('2D Density with shading') import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() # 添加輪廓axes[5].set_title('Contour') import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show() axes[5].contour(xi, yi, zi.reshape(xi.shape)) import numpy as np import matplotlib.pyplot as plt from scipy.stats import kde # 创建数据, 200个点data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200) x, y = data.T # 创建画布, 6个子图fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5)) # 第一个子图, 散点图axes[0].set_title('Scatterplot') axes[0].plot(x, y, 'ko') # 第二个子图, 六边形nbins = 20 axes[1].set_title('Hexbin') axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r) # 2D 直方图axes[2].set_title('2D Histogram') axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r) # 高斯kde k = kde.gaussian_kde(data.T) xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j] zi = k(np.vstack([xi.flatten(), yi.flatten()])) # 密度图axes[3].set_title('Calculate Gaussian KDE') axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r) # 添加阴影axes[4].set_title('2D Density with shading') axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) # 添加轮廓axes[5].set_title('Contour') axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r) axes[5].contour(xi, yi, zi.reshape(xi.shape)) plt.show()使用Matplotlib和scipy進行繪製,結果如下。
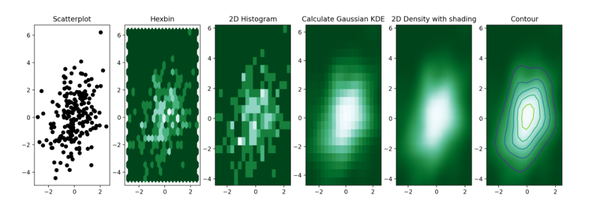
12. 條形圖
條形圖表示多個明確的變量的數值關係。每個變量都為一個條形。條形的大小代表其數值。
import numpy as np import numpy as np import matplotlib.pyplot as plt # 生成随机数据height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) # 创建条形图plt.bar(y_pos, height) # x轴标签plt.xticks(y_pos, bars) # 显示plt.show() import matplotlib.pyplot as plt import numpy as np import matplotlib.pyplot as plt # 生成随机数据height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) # 创建条形图plt.bar(y_pos, height) # x轴标签plt.xticks(y_pos, bars) # 显示plt.show() # 生成隨機數據height = [3, 12, 5, 18, 45] import numpy as np import matplotlib.pyplot as plt # 生成随机数据height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) # 创建条形图plt.bar(y_pos, height) # x轴标签plt.xticks(y_pos, bars) # 显示plt.show() bars = ('A', 'B', 'C', 'D', 'E') import numpy as np import matplotlib.pyplot as plt # 生成随机数据height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) # 创建条形图plt.bar(y_pos, height) # x轴标签plt.xticks(y_pos, bars) # 显示plt.show() y_pos = np.arange(len(bars)) import numpy as np import matplotlib.pyplot as plt # 生成随机数据height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) # 创建条形图plt.bar(y_pos, height) # x轴标签plt.xticks(y_pos, bars) # 显示plt.show() # 創建條形圖plt.bar(y_pos, height) import numpy as np import matplotlib.pyplot as plt # 生成随机数据height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) # 创建条形图plt.bar(y_pos, height) # x轴标签plt.xticks(y_pos, bars) # 显示plt.show() # x軸標籤plt.xticks(y_pos, bars) import numpy as np import matplotlib.pyplot as plt # 生成随机数据height = [3, 12, 5, 18, 45] bars = ('A', 'B', 'C', 'D', 'E') y_pos = np.arange(len(bars)) # 创建条形图plt.bar(y_pos, height) # x轴标签plt.xticks(y_pos, bars) # 显示plt.show()使用Matplotlib的bar()進行繪製,結果如下。
13. 雷達圖
雷達圖,可以可視化多個定量變量的一個或多個系列的值。
每個變量都有自己的軸,所有軸都連接在圖形的中心。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() import pandas as pd import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() from math import pi import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 設置數據df = pd.DataFrame({ import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() 'group': ['A', 'B', 'C', 'D'], import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() 'var1': [38, 1.5, 30, 4], import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() 'var2': [29, 10, 9, 34], import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() 'var3': [8, 39, 23, 24], import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() 'var4': [7, 31, 33, 14], import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() 'var5': [28, 15, 32, 14] import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() }) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 目標數量categories = list(df)[1:] import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() N = len(categories) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 角度angles = [n / float(N) * 2 * pi for n in range(N)] import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() angles += angles[:1] import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 初始化ax = plt.subplot(111, polar=True) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 設置第一處ax.set_theta_offset(pi / 2) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() ax.set_theta_direction(-1) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 添加背景訊息plt.xticks(angles[:-1], categories) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() ax.set_rlabel_position(0) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() plt.ylim(0, 40) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 添加數據圖# 第一個values = df.loc[0].drop('group').values.flatten().tolist() import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() values += values[:1] import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() ax.fill(angles, values, 'b', alpha=0.1) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 第二個values = df.loc[1].drop('group').values.flatten().tolist() import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() values += values[:1] import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() ax.fill(angles, values, 'r', alpha=0.1) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show() # 添加圖例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) import matplotlib.pyplot as plt import pandas as pd from math import pi # 设置数据df = pd.DataFrame({ 'group': ['A', 'B', 'C', 'D'], 'var1': [38, 1.5, 30, 4], 'var2': [29, 10, 9, 34], 'var3': [8, 39, 23, 24], 'var4': [7, 31, 33, 14], 'var5': [28, 15, 32, 14] }) # 目标数量categories = list(df)[1:] N = len(categories) # 角度angles = [n / float(N) * 2 * pi for n in range(N)] angles += angles[:1] # 初始化ax = plt.subplot(111, polar=True) # 设置第一处ax.set_theta_offset(pi / 2) ax.set_theta_direction(-1) # 添加背景訊息plt.xticks(angles[:-1], categories) ax.set_rlabel_position(0) plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7) plt.ylim(0, 40) # 添加数据图# 第一个values = df.loc[0].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A") ax.fill(angles, values, 'b', alpha=0.1) # 第二个values = df.loc[1].drop('group').values.flatten().tolist() values += values[:1] ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B") ax.fill(angles, values, 'r', alpha=0.1) # 添加图例plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1)) # 显示plt.show()使用Matplotlib進行繪製,結果如下。
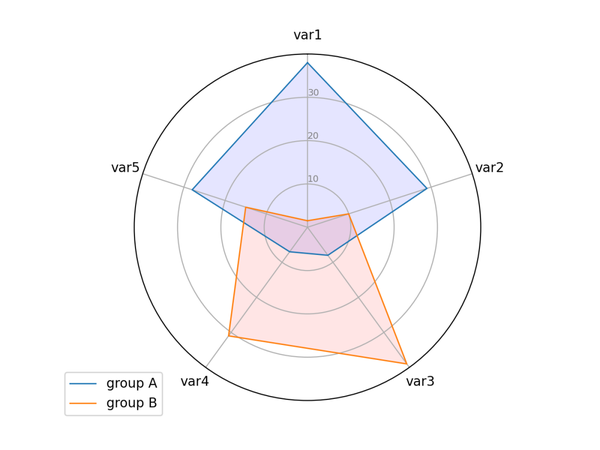
14. 詞云圖
詞云圖是文本數據的視覺表示。
單詞通常是單個的,每個單詞的重要性以字體大小或顏色表示。
from wordcloud import WordCloud from wordcloud import WordCloud import matplotlib.pyplot as plt # 添加词语text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") # 创建词云对象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) # 显示词云图plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show() import matplotlib.pyplot as plt from wordcloud import WordCloud import matplotlib.pyplot as plt # 添加词语text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") # 创建词云对象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) # 显示词云图plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show() # 添加詞語text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") from wordcloud import WordCloud import matplotlib.pyplot as plt # 添加词语text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") # 创建词云对象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) # 显示词云图plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show() # 創建詞云對象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) from wordcloud import WordCloud import matplotlib.pyplot as plt # 添加词语text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") # 创建词云对象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) # 显示词云图plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show() # 顯示詞云圖plt.imshow(wordcloud, interpolation='bilinear') from wordcloud import WordCloud import matplotlib.pyplot as plt # 添加词语text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") # 创建词云对象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) # 显示词云图plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show() plt.axis("off") from wordcloud import WordCloud import matplotlib.pyplot as plt # 添加词语text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") # 创建词云对象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) # 显示词云图plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show() plt.margins(x=0, y=0) from wordcloud import WordCloud import matplotlib.pyplot as plt # 添加词语text=("Python Python Python Matplotlib Chart Wordcloud Boxplot") # 创建词云对象wordcloud = WordCloud(width=480, height=480, margin=0).generate(text) # 显示词云图plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.margins(x=0, y=0) plt.show()使用wordcloud進行繪製,結果如下。

15. 平行座標圖
一個平行座標圖,能夠比較不同系列相同屬性的數值情況。
Pandas可能是繪製平行坐標圖的最佳方式。
import seaborn as sns import seaborn as sns import matplotlib.pyplot as plt from pandas.plotting import parallel_coordinates # 读取数据data = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 创建图表parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) # 显示plt.show() import matplotlib.pyplot as plt import seaborn as sns import matplotlib.pyplot as plt from pandas.plotting import parallel_coordinates # 读取数据data = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 创建图表parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) # 显示plt.show() from pandas.plotting import parallel_coordinates import seaborn as sns import matplotlib.pyplot as plt from pandas.plotting import parallel_coordinates # 读取数据data = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 创建图表parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) # 显示plt.show() # 讀取數據data = sns.load_dataset('iris', data_home='seaborn-data', cache=True) import seaborn as sns import matplotlib.pyplot as plt from pandas.plotting import parallel_coordinates # 读取数据data = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 创建图表parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) # 显示plt.show() # 創建圖表parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) import seaborn as sns import matplotlib.pyplot as plt from pandas.plotting import parallel_coordinates # 读取数据data = sns.load_dataset('iris', data_home='seaborn-data', cache=True) # 创建图表parallel_coordinates(data, 'species', colormap=plt.get_cmap("Set2")) # 显示plt.show()使用Pandas的parallel_coordinates()進行繪製,結果如下。
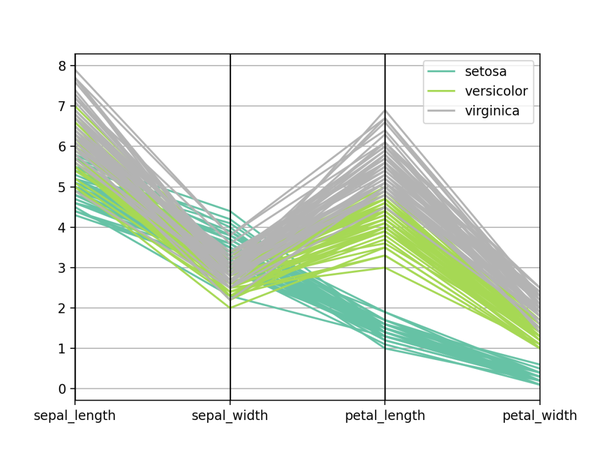
16. 棒棒糖圖
棒棒糖圖其實就是柱狀圖的變形,顯示一個線段和一個圓。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show() import pandas as pd import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show() import numpy as np import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show() # 創建數據df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show() # 排序取值ordered_df = df.sort_values(by='values') import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show() my_range = range(1, len(df.index)+1) import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show() # 創建圖表plt.stem(ordered_df['values']) import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show() plt.xticks(my_range, ordered_df['group']) import matplotlib.pyplot as plt import pandas as pd import numpy as np # 创建数据df = pd.DataFrame({'group': list(map(chr, range(65, 85))), 'values': np.random.uniform(size=20) }) # 排序取值ordered_df = df.sort_values(by='values') my_range = range(1, len(df.index)+1) # 创建图表plt.stem(ordered_df['values']) plt.xticks(my_range, ordered_df['group']) # 显示plt.show()使用Matplotlib的stem()進行繪製,結果如下。
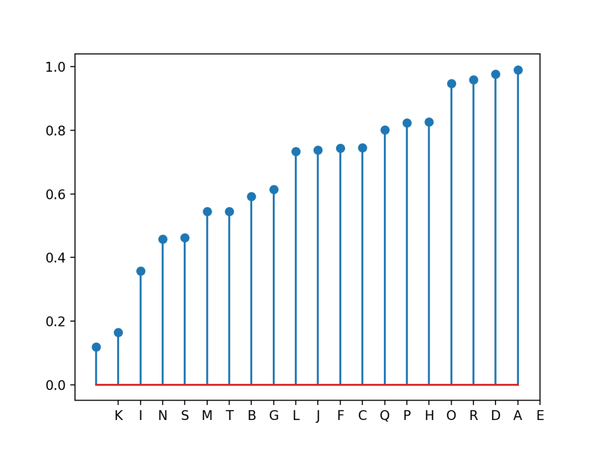
17. 徑向柱圖
徑向柱圖同樣也是條形圖的變形,但是使用極坐標而不是直角坐標系。
繪製起來有點麻煩,而且比柱狀圖準確度低,但更引人注目。
import pandas as pd import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() import matplotlib.pyplot as plt import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() import numpy as np import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 生成數據df = pd.DataFrame( import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() { import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() 'Value': np.random.randint(low=10, high=100, size=50) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() }) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 排序df = df.sort_values(by=['Value']) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 初始化畫布plt.figure(figsize=(20, 10)) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() ax = plt.subplot(111, polar=True) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() plt.axis('off') import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 設置圖表參數upperLimit = 100 import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() lowerLimit = 30 import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() labelPadding = 4 import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 計算最大值max = df['Value'].max() import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 數據下限10, 上限100 import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() slope = (max - lowerLimit) / max import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() heights = slope * df.Value + lowerLimit import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 計算條形圖的寬度width = 2*np.pi / len(df.index) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 計算角度indexes = list(range(1, len(df.index)+1)) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() angles = [element * width for element in indexes] import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 繪製條形圖bars = ax.bar( import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() x=angles, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() height=heights, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() width=width, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() bottom=lowerLimit, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() linewidth=2, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() edgecolor="white", import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() color="#61a4b2", import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() ) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 添加標籤for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 旋轉rotation = np.rad2deg(angle) import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 翻轉alignment = "" import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() if angle >= np.pi/2 and angle < 3*np.pi/2: import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() alignment = "right" import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() rotation = rotation + 180 import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() else: import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() alignment = "left" import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() # 最後添加標籤ax.text( import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() x=angle, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() y=lowerLimit + bar.get_height() + labelPadding, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() s=label, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() ha=alignment, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() va='center', import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() rotation=rotation, import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show() rotation_mode="anchor") import pandas as pd import matplotlib.pyplot as plt import numpy as np # 生成数据df = pd.DataFrame( { 'Name': ['item ' + str(i) for i in list(range(1, 51)) ], 'Value': np.random.randint(low=10, high=100, size=50) }) # 排序df = df.sort_values(by=['Value']) # 初始化画布plt.figure(figsize=(20, 10)) ax = plt.subplot(111, polar=True) plt.axis('off') # 设置图表参数upperLimit = 100 lowerLimit = 30 labelPadding = 4 # 计算最大值max = df['Value'].max() # 数据下限10, 上限100 slope = (max - lowerLimit) / max heights = slope * df.Value + lowerLimit # 计算条形图的宽度width = 2*np.pi / len(df.index) # 计算角度indexes = list(range(1, len(df.index)+1)) angles = [element * width for element in indexes] # 绘制条形图bars = ax.bar( x=angles, height=heights, width=width, bottom=lowerLimit, linewidth=2, edgecolor="white", color="#61a4b2", ) # 添加标签for bar, angle, height, label in zip(bars,angles, heights, df["Name"]): # 旋转rotation = np.rad2deg(angle) # 翻转alignment = "" if angle >= np.pi/2 and angle < 3*np.pi/2: alignment = "right" rotation = rotation + 180 else: alignment = "left" # 最后添加标签ax.text( x=angle, y=lowerLimit + bar.get_height() + labelPadding, s=label, ha=alignment, va='center', rotation=rotation, rotation_mode="anchor") plt.show()使用Matplotlib進行繪製,結果如下。

18. 矩形樹圖
矩形樹圖是一種常見的表達『層級數據』『樹狀數據』的可視化形式。
它主要用面積的方式,便於突出展現出『樹』的各層級中重要的節點。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt import squarify import pandas as pd # 创建数据df = pd.DataFrame({'nb_people': [8, 3, 4, 2], 'group': ["group A", "group B", "group C", "group D"]}) # 绘图显示squarify.plot(sizes=df['nb_people'], label=df['group'], alpha=.8 ) plt.axis('off') plt.show() import squarify import matplotlib.pyplot as plt import squarify import pandas as pd # 创建数据df = pd.DataFrame({'nb_people': [8, 3, 4, 2], 'group': ["group A", "group B", "group C", "group D"]}) # 绘图显示squarify.plot(sizes=df['nb_people'], label=df['group'], alpha=.8 ) plt.axis('off') plt.show() import pandas as pd import matplotlib.pyplot as plt import squarify import pandas as pd # 创建数据df = pd.DataFrame({'nb_people': [8, 3, 4, 2], 'group': ["group A", "group B", "group C", "group D"]}) # 绘图显示squarify.plot(sizes=df['nb_people'], label=df['group'], alpha=.8 ) plt.axis('off') plt.show() # 創建數據df = pd.DataFrame({'nb_people': [8, 3, 4, 2], 'group': ["group A", "group B", "group C", "group D"]}) import matplotlib.pyplot as plt import squarify import pandas as pd # 创建数据df = pd.DataFrame({'nb_people': [8, 3, 4, 2], 'group': ["group A", "group B", "group C", "group D"]}) # 绘图显示squarify.plot(sizes=df['nb_people'], label=df['group'], alpha=.8 ) plt.axis('off') plt.show() # 繪圖顯示squarify.plot(sizes=df['nb_people'], label=df['group'], alpha=.8 ) import matplotlib.pyplot as plt import squarify import pandas as pd # 创建数据df = pd.DataFrame({'nb_people': [8, 3, 4, 2], 'group': ["group A", "group B", "group C", "group D"]}) # 绘图显示squarify.plot(sizes=df['nb_people'], label=df['group'], alpha=.8 ) plt.axis('off') plt.show() plt.axis('off') import matplotlib.pyplot as plt import squarify import pandas as pd # 创建数据df = pd.DataFrame({'nb_people': [8, 3, 4, 2], 'group': ["group A", "group B", "group C", "group D"]}) # 绘图显示squarify.plot(sizes=df['nb_people'], label=df['group'], alpha=.8 ) plt.axis('off') plt.show()使用squarify庫進行繪製,結果如下。

19. 維恩圖
維恩圖,顯示不同組之間所有可能的關係。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt from matplotlib_venn import venn2 # 创建图表venn2(subsets=(10, 5, 2), set_labels=('Group A', 'Group B')) # 显示plt.show() from matplotlib_venn import venn2 import matplotlib.pyplot as plt from matplotlib_venn import venn2 # 创建图表venn2(subsets=(10, 5, 2), set_labels=('Group A', 'Group B')) # 显示plt.show() # 創建圖表venn2(subsets=(10, 5, 2), set_labels=('Group A', 'Group B')) import matplotlib.pyplot as plt from matplotlib_venn import venn2 # 创建图表venn2(subsets=(10, 5, 2), set_labels=('Group A', 'Group B')) # 显示plt.show()使用matplotlib_venn庫進行繪製,結果如下。

20. 圓環圖
圓環圖,本質上就是一個餅圖,中間切掉了一個區域。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) # 在中心添加一个圆, 生成环形图my_circle = plt.Circle((0, 0), 0.7, color='white') p = plt.gcf() p.gca().add_artist(my_circle) plt.show() # 創建數據size_of_groups = [12, 11, 3, 30] import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) # 在中心添加一个圆, 生成环形图my_circle = plt.Circle((0, 0), 0.7, color='white') p = plt.gcf() p.gca().add_artist(my_circle) plt.show() # 生成餅圖plt.pie(size_of_groups) import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) # 在中心添加一个圆, 生成环形图my_circle = plt.Circle((0, 0), 0.7, color='white') p = plt.gcf() p.gca().add_artist(my_circle) plt.show() # 在中心添加一個圓, 生成環形圖my_circle = plt.Circle((0, 0), 0.7, color='white') import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) # 在中心添加一个圆, 生成环形图my_circle = plt.Circle((0, 0), 0.7, color='white') p = plt.gcf() p.gca().add_artist(my_circle) plt.show() p = plt.gcf() import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) # 在中心添加一个圆, 生成环形图my_circle = plt.Circle((0, 0), 0.7, color='white') p = plt.gcf() p.gca().add_artist(my_circle) plt.show() p.gca().add_artist(my_circle) import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) # 在中心添加一个圆, 生成环形图my_circle = plt.Circle((0, 0), 0.7, color='white') p = plt.gcf() p.gca().add_artist(my_circle) plt.show()使用Matplotlib進行繪製,結果如下。
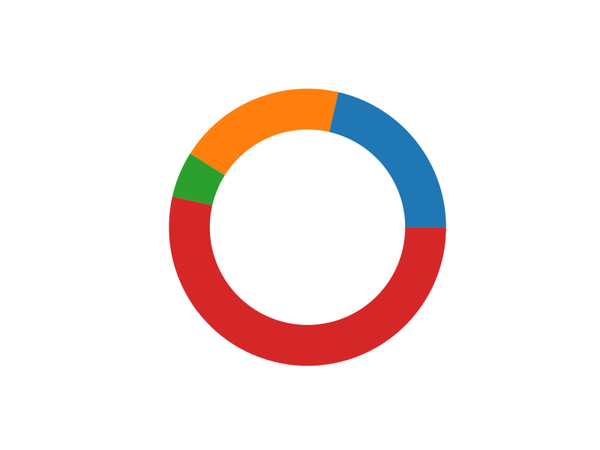
21. 餅圖
餅圖,最常見的可視化圖表之一。
將圓劃分成一個個扇形區域,每個區域代表在整體中所佔的比例。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) plt.show() # 創建數據size_of_groups = [12, 11, 3, 30] import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) plt.show() # 生成餅圖plt.pie(size_of_groups) import matplotlib.pyplot as plt # 创建数据size_of_groups = [12, 11, 3, 30] # 生成饼图plt.pie(size_of_groups) plt.show()使用Matplotlib進行繪製,結果如下。
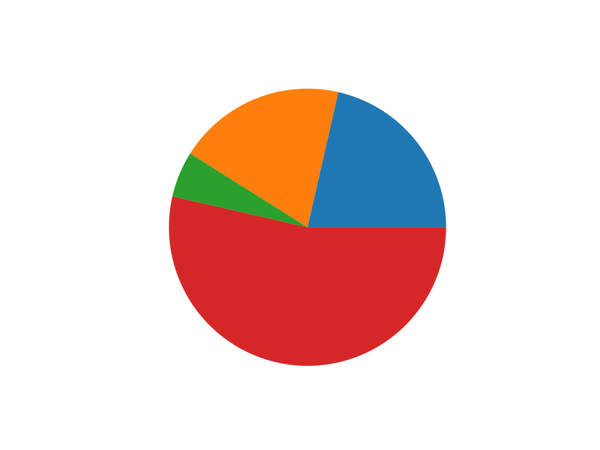
22. 樹圖
樹圖主要用來可視化樹形數據結構,是一種特殊的層次類型,具有唯一的根節點,左子樹,和右子樹。
import pandas as pd import pandas as pd from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage # 读取数据df = pd.read_csv('mtcars.csv') df = df.set_index('model') # 计算每个样本之间的距离Z = linkage(df, 'ward') # 绘图dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) # 显示plt.show() from matplotlib import pyplot as plt import pandas as pd from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage # 读取数据df = pd.read_csv('mtcars.csv') df = df.set_index('model') # 计算每个样本之间的距离Z = linkage(df, 'ward') # 绘图dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) # 显示plt.show() from scipy.cluster.hierarchy import dendrogram, linkage import pandas as pd from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage # 读取数据df = pd.read_csv('mtcars.csv') df = df.set_index('model') # 计算每个样本之间的距离Z = linkage(df, 'ward') # 绘图dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) # 显示plt.show() # 讀取數據df = pd.read_csv('mtcars.csv') import pandas as pd from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage # 读取数据df = pd.read_csv('mtcars.csv') df = df.set_index('model') # 计算每个样本之间的距离Z = linkage(df, 'ward') # 绘图dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) # 显示plt.show() df = df.set_index('model') import pandas as pd from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage # 读取数据df = pd.read_csv('mtcars.csv') df = df.set_index('model') # 计算每个样本之间的距离Z = linkage(df, 'ward') # 绘图dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) # 显示plt.show() # 計算每個樣本之間的距離Z = linkage(df, 'ward') import pandas as pd from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage # 读取数据df = pd.read_csv('mtcars.csv') df = df.set_index('model') # 计算每个样本之间的距离Z = linkage(df, 'ward') # 绘图dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) # 显示plt.show() # 繪圖dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) import pandas as pd from matplotlib import pyplot as plt from scipy.cluster.hierarchy import dendrogram, linkage # 读取数据df = pd.read_csv('mtcars.csv') df = df.set_index('model') # 计算每个样本之间的距离Z = linkage(df, 'ward') # 绘图dendrogram(Z, leaf_rotation=90, leaf_font_size=8, labels=df.index) # 显示plt.show()使用Scipy進行繪製,結果如下。
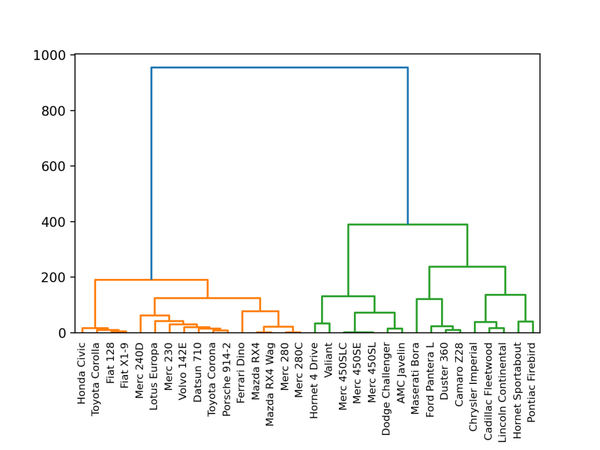
23. 氣泡圖
氣泡圖,表示層次結構及數值大小。
import circlify import matplotlib.pyplot as plt # 創建畫布, 包含一個子圖fig, ax = plt.subplots(figsize=(14, 14)) # 標題ax.set_title('Repartition of the world population') # 移除坐標軸ax.axis('off') # 人口數據data = [{'id': 'World', 'datum': 6964195249, 'children': [ {'id': "North America", 'datum': 450448697, 'children': [ {'id': "United States", 'datum': 308865000}, {'id': "Mexico", 'datum': 107550697}, {'id': "Canada", 'datum': 34033000} ]}, {'id': "South America", 'datum': 278095425, 'children': [ {'id': "Brazil", 'datum': 192612000}, {'id': "Colombia", 'datum': 45349000}, {'id': "Argentina", 'datum': 40134425} ]}, {'id': "Europe", 'datum': 209246682, 'children': [ {'id': "Germany", 'datum': 81757600}, {'id': "France", 'datum': 65447374}, {'id': "United Kingdom", 'datum': 62041708} ]}, {'id': "Africa", 'datum': 311929000, 'children': [ {'id': "Nigeria", 'datum': 154729000}, {'id': "Ethiopia", 'datum': 79221000}, {'id': "Egypt", 'datum': 77979000} ]}, {'id': "Asia", 'datum': 2745929500, 'children': [ {'i d': "China", 'datum': 1336335000}, {'id': "India", 'datum': 1178225000}, {'id': "Indonesia", 'datum': 231369500} ]} ]}] # 使用circlify()計算, 獲取圓的大小, 位置circles = circlify.circlify( data, show_enclosure=False,target_enclosure=circlify.Circle(x=0, y=0, r=1) ) lim = max( max( abs(circle.x) + circle.r, abs(circle.y) + circle.r, ) for circle in circles ) plt.xlim(-lim, lim) plt.ylim(-lim, lim) for circle in circles: if circle.level != 2: continue x, y, r = circle ax.add_patch(plt.Circle((x, y), r, alpha=0.5, linewidth=2, color="lightblue")) for circle in circles: if circle.level != 3: continue x, y, r = circle label = circle.ex["id"] ax.add_patch(plt.Circle((x, y), r, alpha=0.5, linewidth=2, color="#69b3a2")) plt.annotate(label, (x, y), ha='center', color="white") for circle in circles: if circle.level != 2: continue x, y, r = circle label = circle.ex["id"] plt.annotate(label, (x, y), va='center', ha='center', bbox=dict(facecolor='white', edgecolor='black', boxstyle='round', pad=.5)) plt.show()使用Circlify進行繪製,結果如下。
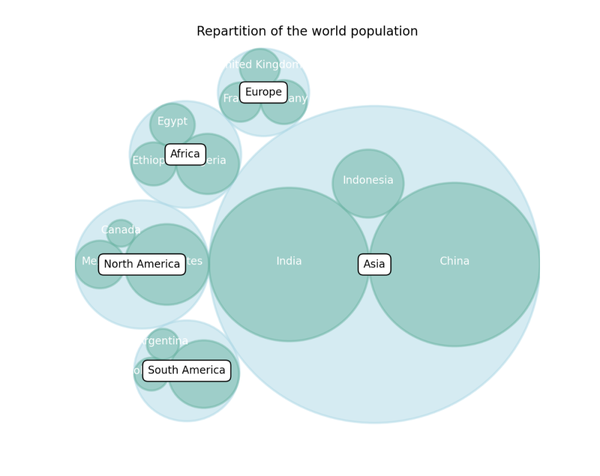
24. 折線圖
折線圖是最常見的圖表類型之一。
將各個數據點標誌連接起來的圖表,用於展現數據的變化趨勢。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt import numpy as np # 创建数据values = np.cumsum(np.random.randn(1000, 1)) # 绘制图表plt.plot(values) plt.show() import numpy as np import matplotlib.pyplot as plt import numpy as np # 创建数据values = np.cumsum(np.random.randn(1000, 1)) # 绘制图表plt.plot(values) plt.show() # 創建數據values = np.cumsum(np.random.randn(1000, 1)) import matplotlib.pyplot as plt import numpy as np # 创建数据values = np.cumsum(np.random.randn(1000, 1)) # 绘制图表plt.plot(values) plt.show() # 繪製圖表plt.plot(values) import matplotlib.pyplot as plt import numpy as np # 创建数据values = np.cumsum(np.random.randn(1000, 1)) # 绘制图表plt.plot(values) plt.show()使用Matplotlib進行繪製,結果如下。
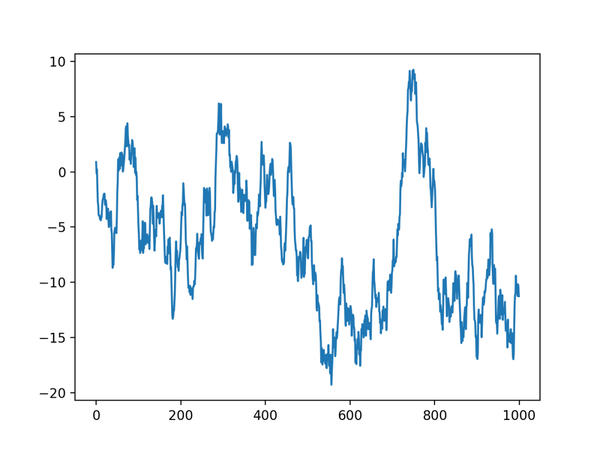
25. 面積圖
面積圖和折線圖非常相似,區別在於和x坐標軸間是否被顏色填充。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y = [1, 4, 6, 8, 4] # 生成图表plt.fill_between(x, y) plt.show() # 創建數據x = range(1, 6) import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y = [1, 4, 6, 8, 4] # 生成图表plt.fill_between(x, y) plt.show() y = [1, 4, 6, 8, 4] import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y = [1, 4, 6, 8, 4] # 生成图表plt.fill_between(x, y) plt.show() # 生成圖表plt.fill_between(x, y) import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y = [1, 4, 6, 8, 4] # 生成图表plt.fill_between(x, y) plt.show()使用Matplotlib的fill_between()進行繪製,結果如下。
26. 堆疊面積圖
堆疊面積圖表示若干個數值變量的數值演變。
每個顯示在彼此的頂部,易於讀取總數,但較難準確讀取每個的值。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] # 生成图表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show() # 創建數據x = range(1, 6) import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] # 生成图表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show() y1 = [1, 4, 6, 8, 9] import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] # 生成图表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show() y2 = [2, 2, 7, 10, 12] import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] # 生成图表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show() y3 = [2, 8, 5, 10, 6] import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] # 生成图表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show() # 生成圖表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] # 生成图表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show() plt.legend(loc='upper left') import matplotlib.pyplot as plt # 创建数据x = range(1, 6) y1 = [1, 4, 6, 8, 9] y2 = [2, 2, 7, 10, 12] y3 = [2, 8, 5, 10, 6] # 生成图表plt.stackplot(x, y1, y2, y3, labels=['A', 'B', 'C']) plt.legend(loc='upper left') plt.show()使用Matplotlib的stackplot()進行繪製,結果如下。
27. 河流圖
河流圖是一種特殊的流圖, 它主要用來表示事件或主題等在一段時間內的變化。
圍繞著中心軸顯示,且邊緣是圓形的,從而形成流動的形狀。
import matplotlib.pyplot as plt import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() import numpy as np import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() from scipy import stats import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() # 添加數據x = np.arange(1990, 2020) import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() y = [np.random.randint(0, 5, size=30) for _ in range(5)] import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() def gaussian_smooth(x, y, grid, sd): import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() """平滑曲線""" import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() weights = weights / weights.sum(0) import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() return (weights * y).sum(1) import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() # 自定義顏色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() # 創建畫布fig, ax = plt.subplots(figsize=(10, 7)) import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() # 生成圖表grid = np.linspace(1985, 2025, num=500) import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show() ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") import matplotlib.pyplot as plt import numpy as np from scipy import stats # 添加数据x = np.arange(1990, 2020) y = [np.random.randint(0, 5, size=30) for _ in range(5)] def gaussian_smooth(x, y, grid, sd): """平滑曲线""" weights = np.transpose([stats.norm.pdf(grid, m, sd) for m in x]) weights = weights / weights.sum(0) return (weights * y).sum(1) # 自定义颜色COLORS = ["#D0D1E6", "#A6BDDB", "#74A9CF", "#2B8CBE", "#045A8D"] # 创建画布fig, ax = plt.subplots(figsize=(10, 7)) # 生成图表grid = np.linspace(1985, 2025, num=500) y_smoothed = [gaussian_smooth(x, y_, grid, 1) for y_ in y] ax.stackplot(grid, y_smoothed, colors=COLORS, baseline="sym") # 显示plt.show()先使用Matplotlib繪製堆積圖,設置stackplot()的baseline參數,可將數據圍繞x軸展示。
再通過scipy.interpolate平滑曲線,最終結果如下。
28. 時間序列圖
時間序列圖是指能夠展示數值演變的所有圖表。
比如折線圖、柱狀圖、面積圖等等。
import numpy as np import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() import seaborn as sns import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() import pandas as pd import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() import matplotlib.pyplot as plt import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() # 創建數據my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() df = pd.DataFrame({ import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() "country": np.repeat(my_count, 10), import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() "years": list(range(2000, 2010)) * 16, import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() "value": np.random.rand(160) import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() }) import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() # 創建網格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() # 添加曲線圖g = g.map(plt.plot, 'years', 'value') import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() # 面積圖g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() # 標題g = g.set_titles("{col_name}") import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() # 總標題plt.subplots_adjust(top=0.92) import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show() g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') import numpy as np import seaborn as sns import pandas as pd import matplotlib.pyplot as plt # 创建数据my_count = ["France", "Australia", "Japan", "USA", "Germany", "Congo", "China", "England", "Spain", "Greece", "Marocco", "South Africa", "Indonesia", "Peru", "Chili", "Brazil"] df = pd.DataFrame({ "country": np.repeat(my_count, 10), "years": list(range(2000, 2010)) * 16, "value": np.random.rand(160) }) # 创建网格g = sns.FacetGrid(df, col='country', hue='country', col_wrap=4, ) # 添加曲线图g = g.map(plt.plot, 'years', 'value') # 面积图g = g.map(plt.fill_between, 'years', 'value', alpha=0.2).set_titles("{col_name} country") # 标题g = g.set_titles("{col_name}") # 总标题plt.subplots_adjust(top=0.92) g = g.fig.suptitle('Evolution of the value of stuff in 16 countries') # 显示plt.show()下面以一個時間序列面積圖為例,顯示多組數據,結果如下。
29. 地圖
所有的地理空間數據分析應該都離不開地圖吧!
import pandas as pd import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') import folium import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') # 創建地圖對象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') # 創建圖標數據data = pd.DataFrame({ import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') 'value': [10, 12, 40, 70, 23, 43, 100, 43] import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') }, dtype=str) import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') # 添加訊息for i in range(0,len(data)): import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') folium.Marker( import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') location=[data.iloc[i]['lat'], data.iloc[i]['lon']], import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') popup=data.iloc[i]['name'], import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html') ).add_to(m) import pandas as pd import folium # 创建地图对象m = folium.Map(location=[20, 0], tiles="OpenStreetMap", zoom_start=2) # 创建图标数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加訊息for i in range(0,len(data)): folium.Marker( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], ).add_to(m) # 保存m.save('map.html')使用Folium繪製谷歌地圖風格的地圖,結果如下。
30. 等值域地圖
等值域地圖,相同數值範圍,著色相同。
import pandas as pd import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') import folium import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') # 創建地圖對象m = folium.Map(location=[40, -95], zoom_start=4) import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') # 讀取數據state_geo = f"us-states.json" import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') state_unemployment = f"US_Unemployment_Oct2012.csv" import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') state_data = pd.read_csv(state_unemployment) import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') folium.Choropleth( import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') geo_data=state_geo, import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') name="choropleth", import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') data=state_data, import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') columns=["State", "Unemployment"], import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') key_on="feature.id", import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') fill_color="YlGn", import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') fill_opacity=0.7, import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') line_opacity=.1, import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') legend_name="Unemployment Rate (%)", import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') ).add_to(m) import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html') folium.LayerControl().add_to(m) import pandas as pd import folium # 创建地图对象m = folium.Map(location=[40, -95], zoom_start=4) # 读取数据state_geo = f"us-states.json" state_unemployment = f"US_Unemployment_Oct2012.csv" state_data = pd.read_csv(state_unemployment) folium.Choropleth( geo_data=state_geo, name="choropleth", data=state_data, columns=["State", "Unemployment"], key_on="feature.id", fill_color="YlGn", fill_opacity=0.7, line_opacity=.1, legend_name="Unemployment Rate (%)", ).add_to(m) folium.LayerControl().add_to(m) # 保存m.save('choropleth-map.html')使用Folium的choropleth()進行繪製,結果如下。
31. 網格地圖
Hexbin地圖,美國大選投票經常看見。
import pandas as pd import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() import geopandas as gpd import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() import matplotlib.pyplot as plt import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() # 讀取數據file = "us_states_hexgrid.geojson.json" import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() geoData = gpd.read_file(file) import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() mariageData = pd.read_csv("State_mariage_rate.csv") import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() geoData['state'] = geoData['google_name'].str.replace(' (United States)','') import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() geoData = geoData.set_index('state').join(mariageData.set_index('state')) import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() # 繪圖geoData.plot( import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() ax=ax, import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() column="y_2015", import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() cmap="BuPu", import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() norm=plt.Normalize(vmin=2, vmax=13), import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() edgecolor='black', import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() linewidth=.5 import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() ); import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() # 不顯示坐標軸ax.axis('off') import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() # 標題, 副標題,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() # 每個網格for idx, row in geoData.iterrows(): import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() ax.annotate( import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() s=row['iso3166_2'], import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() xy=row['centroid'].coords[0], import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() horizontalalignment='center', import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() va='center', import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() color="white" import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() ) import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() # 添加顏色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show() fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); import pandas as pd import geopandas as gpd import matplotlib.pyplot as plt # 读取数据file = "us_states_hexgrid.geojson.json" geoData = gpd.read_file(file) geoData['centroid'] = geoData['geometry'].apply(lambda x: x.centroid) mariageData = pd.read_csv("State_mariage_rate.csv") geoData['state'] = geoData['google_name'].str.replace(' (United States)','') geoData = geoData.set_index('state').join(mariageData.set_index('state')) # 初始化fig, ax = plt.subplots(1, figsize=(6, 4)) # 绘图geoData.plot( ax=ax, column="y_2015", cmap="BuPu", norm=plt.Normalize(vmin=2, vmax=13), edgecolor='black', linewidth=.5 ); # 不显示坐标轴ax.axis('off') # 标题, 副标题,作者ax.annotate('Mariage rate in the US', xy=(10, 340), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=14, color='black') ax.annotate('Yes, people love to get married in Vegas', xy=(10, 320), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=11, color='#808080') ax.annotate('xiao F', xy=(400, 0), xycoords='axes pixels', horizontalalignment='left', verticalalignment='top', fontsize=8, color='#808080') # 每个网格for idx, row in geoData.iterrows(): ax.annotate( s=row['iso3166_2'], xy=row['centroid'].coords[0], horizontalalignment='center', va='center', color="white" ) # 添加颜色sm = plt.cm.ScalarMappable(cmap='BuPu', norm=plt.Normalize(vmin=2, vmax=13)) fig.colorbar(sm, orientation="horizontal", aspect=50, fraction=0.005, pad=0 ); # 显示plt.show()使用geopandas和matplotlib進行繪製,結果如下。
32. 變形地圖
故名思義,就是形狀發生改變的地圖。
其中每個區域的形狀,會根據數值發生扭曲變化。
這裡沒有相關的代碼範例,直接上個圖好了。
33. 連接映射地圖
連接地圖可以顯示地圖上幾個位置之間的連接關係。
航空上經常用到的飛線圖,應該是這個的升級版。
from mpl_toolkits.basemap import Basemap from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() import matplotlib.pyplot as plt from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() import pandas as pd from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() # 數據cities = { from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() } from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() # 創建地圖m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() m.drawmapboundary(fill_color='white', linewidth=0) from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() m.fillcontinents(color='#f2f2f2', alpha=0.7) from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() m.drawcoastlines(linewidth=0.1, color="white") from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() # 循環建立連接for startIndex, startRow in df.iterrows(): from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() for endIndex in range(startIndex, len(df.index)): from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() endRow = df.iloc[endIndex] from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() # 添加城市名稱for i, row in df.iterrows(): from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show() plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import pandas as pd # 数据cities = { 'city': ["Paris", "Melbourne", "Saint.Petersburg", "Abidjan", "Montreal", "Nairobi", "Salvador"], 'lon': [2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [49, -38, 59.93, 5.33, 45.52, -1.29, -12.97] } df = pd.DataFrame(cities, columns=['city', 'lon', 'lat']) # 创建地图m = Basemap(llcrnrlon=-179, llcrnrlat=-60, urcrnrlon=179, urcrnrlat=70, projection='merc') m.drawmapboundary(fill_color='white', linewidth=0) m.fillcontinents(color='#f2f2f2', alpha=0.7) m.drawcoastlines(linewidth=0.1, color="white") # 循环建立连接for startIndex, startRow in df.iterrows(): for endIndex in range(startIndex, len(df.index)): endRow = df.iloc[endIndex] m.drawgreatcircle(startRow.lon, startRow.lat, endRow.lon, endRow.lat, linewidth=1, color='#69b3a2'); # 添加城市名称for i, row in df.iterrows(): plt.annotate(row.city, xy=m(row.lon + 3, row.lat), verticalalignment='center') plt.show()使用basemap繪製,結果如下。
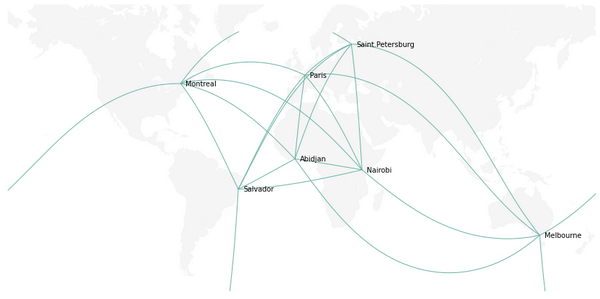
34. 氣泡地圖
氣泡地圖,使用不同尺寸的圓來表示該地理坐標的數值。
import folium import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') import pandas as pd import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') # 創建地圖對象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') # 坐標點數據data = pd.DataFrame({ import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') 'value': [10, 12, 40, 70, 23, 43, 100, 43] import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') }, dtype=str) import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') # 添加氣泡for i in range(0, len(data)): import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') folium.Circle( import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') location=[data.iloc[i]['lat'], data.iloc[i]['lon']], import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') popup=data.iloc[i]['name'], import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') radius=float(data.iloc[i]['value'])*20000, import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') color='crimson', import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') fill=True, import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') fill_color='crimson' import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html') ).add_to(m) import folium import pandas as pd # 创建地图对象m = folium.Map(location=[20,0], tiles="OpenStreetMap", zoom_start=2) # 坐标点数据data = pd.DataFrame({ 'lon': [-58, 2, 145, 30.32, -4.03, -73.57, 36.82, -38.5], 'lat': [-34, 49, -38, 59.93, 5.33, 45.52, -1.29, -12.97], 'name': ['Buenos Aires', 'Paris', 'melbourne', 'St Petersbourg', 'Abidjan', 'Montreal', 'Nairobi', 'Salvador'], 'value': [10, 12, 40, 70, 23, 43, 100, 43] }, dtype=str) # 添加气泡for i in range(0, len(data)): folium.Circle( location=[data.iloc[i]['lat'], data.iloc[i]['lon']], popup=data.iloc[i]['name'], radius=float(data.iloc[i]['value'])*20000, color='crimson', fill=True, fill_color='crimson' ).add_to(m) # 保存m.save('bubble-map.html')使用Folium的Circle()進行繪製,結果如下。
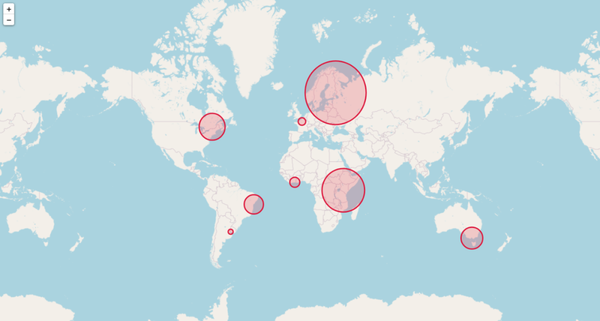
35. 和弦圖
和弦圖表示若干個實體(節點)之間的流或連接。
每個實體(節點)有圓形佈局外部的一個片段表示。
然後在每個實體之間繪製弧線,弧線的大小與流的關係成正比。
from chord import Chord from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") matrix = [ from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") [0, 5, 6, 4, 7, 4], from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") [5, 0, 5, 4, 6, 5], from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") [6, 5, 0, 4, 5, 5], from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") [4, 4, 4, 0, 5, 5], from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") [7, 6, 5, 5, 0, 4], from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") [4, 5, 5, 5, 4, 0], from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") ] from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html") names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] from chord import Chord matrix = [ [0, 5, 6, 4, 7, 4], [5, 0, 5, 4, 6, 5], [6, 5, 0, 4, 5, 5], [4, 4, 4, 0, 5, 5], [7, 6, 5, 5, 0, 4], [4, 5, 5, 5, 4, 0], ] names = ["Action", "Adventure", "Comedy", "Drama", "Fantasy", "Thriller"] # 保存Chord(matrix, names).to_html("chord-diagram.html")使用Chord庫進行繪製,結果如下。
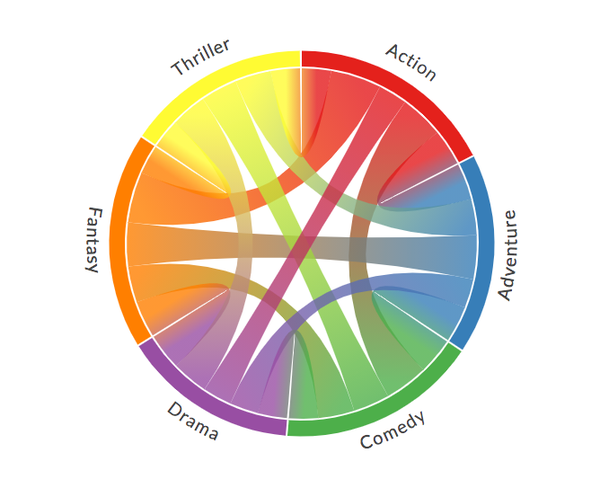
36. 網狀圖
網狀圖顯示的是一組實體之間的連接關係。
每個實體由一個節點表示,節點之間通過線段連接。
import pandas as pd import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() import numpy as np import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() import networkx as nx import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() import matplotlib.pyplot as plt import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() # 創建數據ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() df = pd.DataFrame( import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() # 計算相關性corr = df.corr() import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() # 轉換links = corr.stack().reset_index() import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() links.columns = ['var1', 'var2', 'value'] import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() # 保持相關性超過一個閾值, 刪除自相關性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() # 生成圖G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show() # 繪製網絡nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) import pandas as pd import numpy as np import networkx as nx import matplotlib.pyplot as plt # 创建数据ind1 = [5, 10, 3, 4, 8, 10, 12, 1, 9, 4] ind5 = [1, 1, 13, 4, 18, 5, 2, 11, 3, 8] df = pd.DataFrame( {'A': ind1, 'B': ind1 + np.random.randint(10, size=(10)), 'C': ind1 + np.random.randint(10, size=(10)), 'D': ind1 + np.random.randint(5, size=(10)), 'E': ind1 + np.random.randint(5, size=(10)), 'F': ind5, 'G': ind5 + np.random.randint(5, size=(10)), 'H': ind5 + np.random.randint(5, size=(10)), 'I': ind5 + np.random.randint(5, size=(10)), 'J': ind5 + np.random.randint(5, size=(10))}) # 计算相关性corr = df.corr() # 转换links = corr.stack().reset_index() links.columns = ['var1', 'var2', 'value'] # 保持相关性超过一个阈值, 删除自相关性links_filtered = links.loc[(links['value'] > 0.8) & (links['var1'] != links['var2'])] # 生成图G = nx.from_pandas_edgelist(links_filtered, 'var1', 'var2') # 绘制网络nx.draw(G, with_labels=True, node_color='orange', node_size=400, edge_color='black', linewidths=1, font_size=15) # 显示plt.show()使用NetworkX庫進行繪製,結果如下。
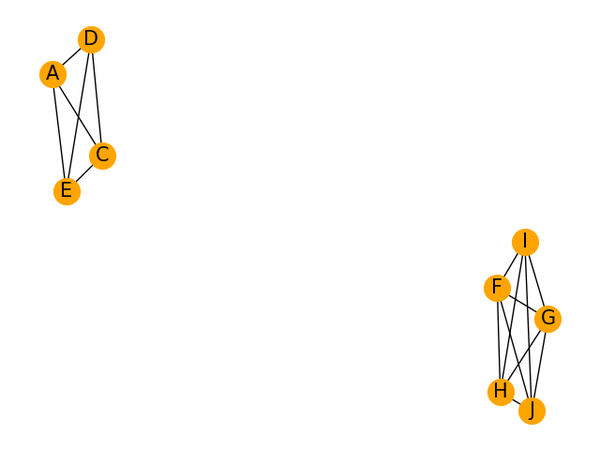
37. 桑基圖
桑基圖是一種特殊的流圖。
它主要用來表示原材料、能量等如何從初始形式經過中間過程的加工、轉化到達最終形式。
Plotly可能是創建桑基圖的最佳工具,通過Sankey()在幾行代碼中獲得一個圖表。
import plotly.graph_objects as go import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") import json import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") # 讀取數據with open('sankey_energy.json') as f: import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") data = json.load(f) import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") # 透明度opacity = 0.4 import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") # 顏色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") for src in data['data'][0]['link']['source']] import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") fig = go.Figure(data=[go.Sankey( import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") valueformat=".0f", import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") valuesuffix="TWh", import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") # 點node=dict( import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") pad=15, import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") thickness=15, import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") line=dict(color = "black", width = 0.5), import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") label=data['data'][0]['node']['label'], import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") color=data['data'][0]['node']['color'] import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") ), import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") # 線link=dict( import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") source=data['data'][0]['link']['source'], import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") target=data['data'][0]['link']['target'], import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") value=data['data'][0]['link']['value'], import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") label=data['data'][0]['link']['label'], import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") color=data['data'][0]['link']['color'] import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") ))]) import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html") font_size=10) import plotly.graph_objects as go import json # 读取数据with open('sankey_energy.json') as f: data = json.load(f) # 透明度opacity = 0.4 # 颜色data['data'][0]['node']['color'] = ['rgba(255,0,255, 0.8)' if color == "magenta" else color for color in data['data'][0]['node']['color']] data['data'][0]['link']['color'] = [data['data'][0]['node']['color'][src].replace("0.8", str(opacity)) for src in data['data'][0]['link']['source']] fig = go.Figure(data=[go.Sankey( valueformat=".0f", valuesuffix="TWh", # 点node=dict( pad=15, thickness=15, line=dict(color = "black", width = 0.5), label=data['data'][0]['node']['label'], color=data['data'][0]['node']['color'] ), # 线link=dict( source=data['data'][0]['link']['source'], target=data['data'][0]['link']['target'], value=data['data'][0]['link']['value'], label=data['data'][0]['link']['label'], color=data['data'][0]['link']['color'] ))]) fig.update_layout(title_text="Energy forecast for 2050<br>Source: Department of Energy & Climate Change, Tom Counsell via <a href='https://bost.ocks.org/mike/sankey/'>Mike Bostock</a>", font_size=10) # 保持fig.write_html("sankey-diagram.html")使用Plotly庫進行繪製,結果如下。
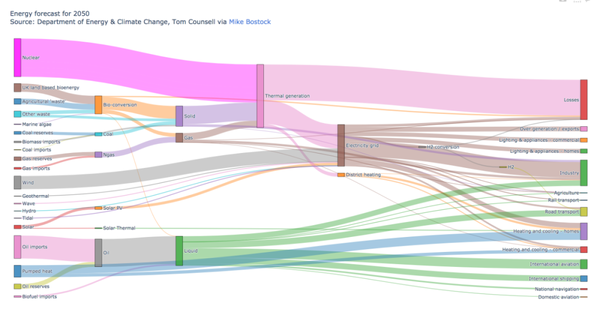
38. 弧線圖
弧線圖是一種特殊的網絡圖。
由代表實體的節點和顯示實體之間關係的弧線組成的。
在弧線圖中,節點沿單個軸顯示,節點間通過圓弧線進行連接。
目前還不知道如何通過Python來構建弧線圖,不過可以使用R或者D3.js。
下面就來看一個通過js生成的弧線圖。
39. 環形佈局關係圖
可視化目標之間的關係,可以減少複雜網絡下觀察混亂。
和弧線圖一樣,也只能通R或者D3.js繪製。
D3.js繪製的範例如下。
40. 動態圖表
動態圖表本質上就是顯示一系列靜態圖表。
可以描述目標從一種狀態到另一種狀態的變化。
import imageio import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) import pandas as pd import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) import matplotlib.pyplot as plt import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 讀取數據data = pd.read_csv('gapminderData.csv') import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 更改格式data['continent'] = pd.Categorical(data['continent']) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 分辨率dpi = 96 import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) filenames = [] import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 每年的數據for i in data.year.unique(): import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 關閉交互式繪圖plt.ioff() import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 篩選數據subsetData = data[data.year == i] import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 生成散點氣泡圖plt.scatter( import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) x=subsetData['lifeExp'], import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) y=subsetData['gdpPercap'], import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) s=subsetData['pop'] / 200000, import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) c=subsetData['continent'].cat.codes, import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 添加相關訊息plt.yscale('log') import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.xlabel("Life Expectancy") import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.ylabel("GDP per Capita") import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.title("Year: " + str(i)) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.ylim(0, 100000) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.xlim(30, 90) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 保存filename = './images/' + str(i) + '.png' import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) filenames.append(filename) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.savefig(fname=filename, dpi=96) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.gca() import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) plt.close(fig) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) # 生成GIF動態圖表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) for filename in filenames: import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image) image = imageio.imread(filename) import imageio import pandas as pd import matplotlib.pyplot as plt # 读取数据data = pd.read_csv('gapminderData.csv') # 更改格式data['continent'] = pd.Categorical(data['continent']) # 分辨率dpi = 96 filenames = [] # 每年的数据for i in data.year.unique(): # 关闭交互式绘图plt.ioff() # 初始化fig = plt.figure(figsize=(680 / dpi, 480 / dpi), dpi=dpi) # 筛选数据subsetData = data[data.year == i] # 生成散点气泡图plt.scatter( x=subsetData['lifeExp'], y=subsetData['gdpPercap'], s=subsetData['pop'] / 200000, c=subsetData['continent'].cat.codes, cmap="Accent", alpha=0.6, edgecolors="white", linewidth=2) # 添加相关訊息plt.yscale('log') plt.xlabel("Life Expectancy") plt.ylabel("GDP per Capita") plt.title("Year: " + str(i)) plt.ylim(0, 100000) plt.xlim(30, 90) # 保存filename = './images/' + str(i) + '.png' filenames.append(filename) plt.savefig(fname=filename, dpi=96) plt.gca() plt.close(fig) # 生成GIF动态图表with imageio.get_writer('result.gif', mode='I', fps=5) as writer: for filename in filenames: image = imageio.imread(filename) writer.append_data(image)以一個動態散點氣泡圖為例,
先用matplotlib繪製圖表圖片,再通過imageio生成GIF,結果如下。
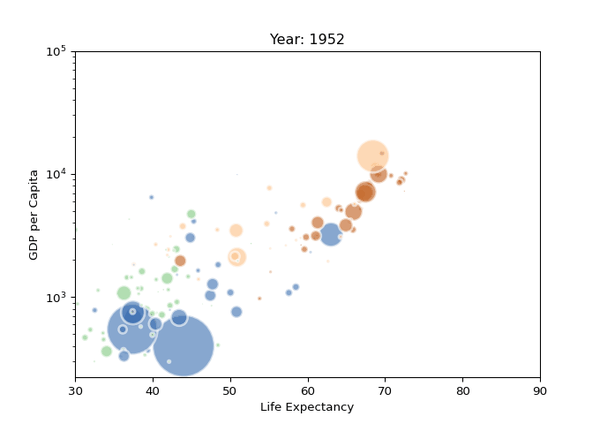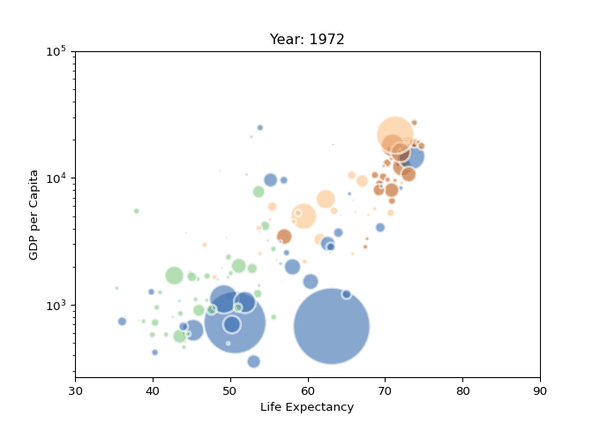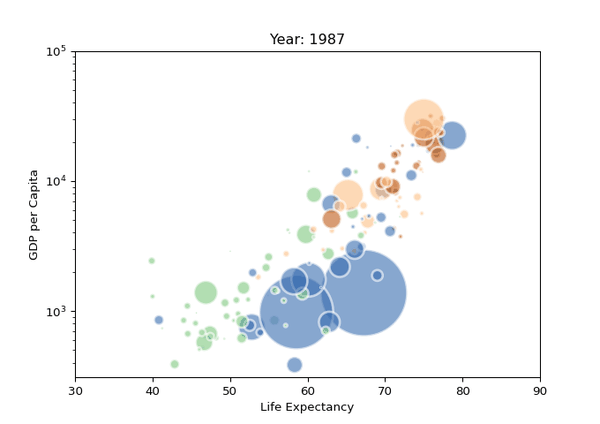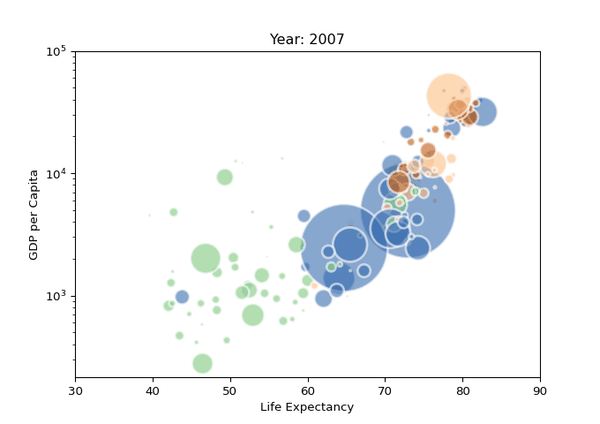
好了,本期的分享就到此結束了。
其中使用到的可視化庫,大部分通過pip install即可完成安裝。
相關代碼及文件已上傳,評論區回复「
有興趣的小伙伴,可以自行去實踐學習一下!