【Tableau】一、數據源連接及操作
背景
接觸Tableau好幾年了,通過找資料自學以及在工作上的不斷學習及實踐,慢慢的對於Tableau的使用越來越熟練,但是隱約覺得知識點太零散沒有體系框架,因此專門找了課程研究學習,為了便於知識點的掌握及後續的鞏固,我將按照課程及自己在工作中的經驗對知識點進行框架的梳理,並一個板塊一個板塊的在知乎上進行記錄。
首先,接觸Tableau的第一步,也就是對數據源的操作,因為有了數據源,你才能夠根據業務對數據進行處理,然後進行後面的可視化。 所以第一章節就是講解數據源連接及操作。
大綱
下圖是本次內容的大綱,如果看不太清楚也不要緊,後面我會拆部分依次進行講解。


內容
數據源部分的內容,主要劃分成了3大部分:
- 可連接的數據
- 數據連接的方式
- 數據源操作
其中第3部分「數據源操作」是本次數據源部分最核心的內容。 我們首先來講第1部分。
1、可連接的數據

(1) 到檔

在工作上主要是用到Microsoft Excel、文本文件和空間檔這3種,Microsoft Excel就是以".xls",".xlsx",".xlsm"結尾的檔;常用的".csv"結尾的檔是文本檔,所以在連接選擇的時候要注意,選擇對應的類型即可,不然可能找不到對應文件的情況;空間檔是在畫地圖不用自帶經緯度時用到的檔。 其他用到的不多,需要用到時,百度即可。
(2) 到伺服器

到伺服器這一部分是用的比較多的,因為稍微數據量大點的公司,都會有自己的資料庫,MySQL或是Oracle,有大數據平臺Hadoop的,也是可以通過連接伺服器連接的。 由於我們公司還有三方數據平臺Google Analytics,所以部分數據還需要連接GA。 公司購買了正版的Tableau,那麼還會多一個Tableau Server的伺服器端,提取的數據源可以上傳到Server上,可以反覆調用,伺服器上其他使用者發佈的數據源,也能夠調用。 由於我截圖的是家裡破解版本,所以沒有Tableau Server選項。 Tableau連接支援的伺服器類型是特別特別多的,基本上都是能夠支援的。
(3) 已保存資料來源

是Tableau本身自帶的一些數據源,你自己保存的數據源也會在這裡顯示。
2、數據連接的方式

- 即時
- 數據提取
數據連接的方式可以分為2種,各自都有自己的應用場景
(1) 即時
當在開發介面做的任何一個操作,Tableau都會將它轉換成一個查詢代碼發送到伺服器,執行查詢以後再將結果反回到Tableau進行顯示
【使用場景】:
- 對數據的準確性要求特別高,以比較短的間隔比如秒級來掌握原始數據發生的變動
- 對數據的保密性要求很高,不允許將數據拷貝,或是保存在其他地方,只能聯接到指定的伺服器上進行操作
- IT基礎設施非常好,伺服器的硬體,網路的頻寬等都很強大 ,可以支持即時的操作形式
(2) 資料提取
為了解決現在大數據特別的多,數據會很大,幾億幾十億的情況,大量數據會給開發操作帶來性能上和實效性方面的延遲
【使用場景】:
使用場景和"即時"相反。
【實際工作中數據提取和數據刷新】:
由於數據源本身數據量大,每天需要刷新的數據量很多,而且本身對實效性也沒有那麼敏感,因此我們採用的是N+1的模式進行數據提取刷新的,就是今天提取刷新昨天的數據,時間間隔會有1天,而且因為需要刷新的數據源很多,根據數據源的重要程度及刷新時間的需求,會進行不同時間的自動刷新設置。 比如很重要的流量、銷售數據,就會每天在最核心的時間段刷新,而不需要每天關注的流程數據源,就可以根據業務需求進行頻次的設置,可以隔2天刷新,或者是設置在下班后的時間段刷新。 一定不要同一時間段刷新,這樣會造成伺服器的負擔,也會使得重要數據源一直在排隊沒有刷新。
3、數據源操作

- 聯接
- 並集
- 數據混合
- 其他特殊數據源的操作
這一部分的內容是數據源部分很核心的內容,是在工作中用Tableau進行取數的第一步,數據分析的原數據都錯誤的話,再怎麼進行數據處理可視化都是徒勞。
如果本身很熟悉資料庫MySQL取數,那麼這一部分就很好掌握,聯接和SQL語句的join的思想是完全一致的。 並集也就是MySQL的UNION ALL。
(1) 聯接
1) 4種聯接類型

上圖為Tableau的聯接介面,左表為"訂單",右表為"退貨",通過連接條件進行連接,可以是單個,也可以是多個,上圖條件就是"訂單"表裡的"訂單ID"字段和"退貨"表裡的"訂單ID"字段進行匹配,相同的就能匹配上,不相同就匹配不上。
兩個表的聯接方式有4種,分別是:
| 方式 | 定義 |
|---|---|
| 內聯接 | 兩個表的交集,兩表匹配不上的部分不返回 |
| 左聯接 | 以左表為準,生成的表將包含左側表中的所有值以及右側表中的對應匹配項,未匹配上的返回null值 |
| 右聯接 | 和左聯接思想一致,只是以右表為準,生成的表將包含右側表中的所有值以及左側表中的對應匹配項,未匹配上的返回null值 |
| 完全外部聯接 | 包含兩個表中的所有值。 當任一表中的值在另一個表中沒有匹配項時,返回null值 |
聯接的4種方式我在這裡不重點詳細講解,會MySQL中join的部分看到就知道在Tableau中如何操作。 我後面會專門寫一篇MySQL的join部分的詳細篇,舉例展示執行結果,對比結果清楚的知道這幾種join的區別。
2)2種聯接方式
第一種:同資料庫聯接
2個表都來自於同一個資料庫,下圖中的「訂單」和"退貨"表都是來自於"範例 - 超市"這個資料庫。 可以看到2個表和「範例 - 超市」資料庫的顏色都是藍色,說明2個表都是來自「範例 - 超市」資料庫的。

第二種:跨資料庫聯接
下圖中的"user_info"來自Excel"user",而"operation"來自MySQL資料庫,並不是來與同一源,從顏色就可以看出,源和表的顏色是一致的,這裡出現了2種顏色。

(2) 並集
並集其實就是MySQL中的UNION ALL操作,也就是將格式相同的不同表合併在一起。
有2種:手動合併、通配符合並
第一種:手動合併
如下圖,先連接到excel表「成績表」,然後表中的3個sheet表是格式一致,不同班級的成績,需要合併,就直接把3個表拖到並集框裡面,最後點擊確定就可以了。

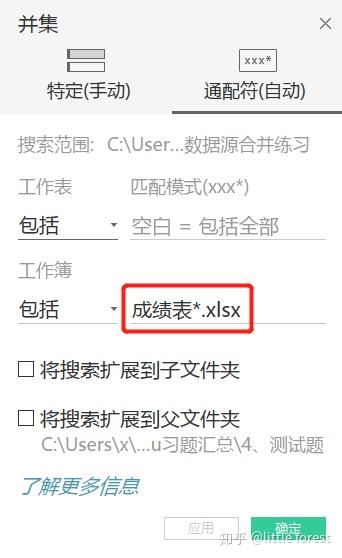
第二種:通配符合並
資料夾有這樣3個Excel表,是3個班的成績,需要把這3個Excel表合併

可以看出Excel表名的只有班級的尾綴不一致,因此我們可以加一個"*"代表通配符,這樣把選中的資料夾下,名字以"成績表"為前綴的所有Excel都合併起來。 Tableau提供了更強大的功能,可以將搜索擴展到子資料夾以及父資料夾,符合匹配條件的都可以合併,如果需要的話直接勾選即可。 這個例子不涉及到子資料夾或是父資料夾,所以不勾選。
(3) 數據混合
1)定義
2個數據源進行混合,1個是主數據源,1個是輔助數據源;2個數據源之間至少有1個字段可以進行關聯;主數據源和輔助數據源並不是絕對的,是由工作表決定的。
注意:2個數據源之間的關係是Tableau工作簿級別,誰是主誰是輔是在工作表級別設置的,它是可以互換的。

從上圖可以看出,2個數據源有相同的欄位"產品名稱",可以混合數據源按照不同維度進行銷售數據的統計。 並且「產品清單」中的「產品型號」和「產品銷售明細」中的「產品編號」其實是統計的同一個字段,只是兩個數據源中的欄位名不一致,可以利用下面要講的編輯關係來手動建立聯繫,從而統計「產品型號」的銷售情況,並知道哪些產品型號是沒有銷售,哪些是有銷售的。
2)編輯關係
關係決定輔助數據源中的數據和主數據源的聯接方式

如上圖,編輯關係有2種,第一種是如果2個數據源的欄位相同,那麼Tableau會自動默認2個字段的關係,比如"產品名稱"這個字段;另一種是可以手動編輯關係,比如"產品清單"中的"產品型號"和"產品銷售明細"中的"產品編號",就可以點擊"添加"手動編輯關係,步驟如下圖:

備註:如果不需要的關係可以手動刪除,自動默認的關係和自定義的關係都可以手動刪除。
下面我們來進行數據混合的演示:

資料混合說明:
a. "產品清單"是主數據源,數據源為藍色,"產品銷售明細"是輔助數據源,數據源為橙色。 工作表中行位置的欄位名有橙色標識的,表示這些欄位是來自於「產品銷售明細」輔助數據源。 沒有顏色標識的標識這些欄位是來自於「產品清單」主數據源。
b. 輔助數據源「產品銷售明細」的維度欄裡面2個字段「產品名稱」和「產品編號」後面都有一個紅色的連接符,這個說明工作表中的數據統計這2個字段已經和主數據源連接了。 這2個字段就是之前我們建立了關係的2個字段,「產品名稱」是本身與主數據源同名,默認關係,「產品編碼」是自定義建立的與主數據源的關係。
c. 工作表裡面銷售量和銷售額都是根據「產品名稱」和「產品型號」進行了聚合。 其中"產
品型號"=PP,"產品型號"=PP_1的銷售數據為null,說明輔助數據源中並沒有PP_1的銷售記錄。
d. 工作表中「使用者名」有部分是"*",說明購買這些產品的使用者並不是一個,"使用者名"=C,說明購買 HH_1的使用者只有C一個人,HH_2顯示為"*",說明購買的人有多個。
3)與左聯接的差異
數據混合看起來有點類似「左聯接」 的操作。 但它只是類似左聯接,和左聯接還是有著本質的差異的。
數據混合:是對2個數據源單獨進行查詢操作,再將結果集聚合到同一粒度,最後類比左聯接得到一個結果集
左聯接:是把關聯操作發送給伺服器,然後進行查詢得到的結果集返回到Tableau,最終以1個數據源的形式保存下來
(4) 其他特殊數據源的操作
這個部分的知識點是在實操時可能會遇到的問題,有一定的小技巧,但是容易被忽視,或是不知道該怎麼操作的情況,我覺得算是比較常見也比較有用的操作技巧。
1)數據提取時按照日期維度聚合
我們在提取數據的時候有這樣的需求:我們的日期維度是以日來統計的,但是我們接下來統計的數據的維度都是以月來統計的。 那麼我們可以在提取數據的時候,就以日期維度「月」來進行數據的聚合,這樣數據源會比較小,可能按日的維度有幾十萬條,但是按照月統計可能就只有幾千條了,所以整個數據體量少了很多。
這個小知識點的操作步驟如下:

2)使用數據解析器
我們在讀取一張Excel表時,是下面這種情況,我們所需要的數據並不是從第一行直接開始。
直接Tableau讀取的話,會出現下圖這種情況,這種格式並不是我們想要的,我們只需要從第3行開始的數據。

這種情況,只需要勾選工作表連接頁面的"已使用數據解析器清理"就可以了,下圖可以清楚看到上面出現的數據提取問題已經處理完成了。

3)數據透視表
我們有時候在讀取Excel數據的時候,很多情況就是左邊表的樣式,會把不同年份的度量值列出好幾列,但其實這幾列值都是同一類數據。 這種在做底層數據處理以及可視化的時候就特別不好操作,我們需要變換成右邊表的格式,將年份作為維度值,就像透視表處理的一樣。

這種情況,只需要按照這個步驟處理即可:「連接」頁面 —>選中要轉換成維度的度量列—>右鍵「數據透視表」—>進行欄位重命名
4)欄位名稱用於第一行中
有的時候在讀取Excel數據表時,欄位名寫的數位形式,預設用Tableau讀取的時候,就會出現下面的右邊圖這樣的形式,不會把第一行直接作為欄位。

這種情況,按照下圖的演示步驟操作即可,處理完后就會變成下面正確的表格。

結束
以上就是第一部分《數據源連接及操作》的所有內容,如有任何錯誤的地方請大家指正,謝謝!