前深度學習時代CTR預估模型的演化之路
這裡是「王喆的機器學習筆記」的第十一篇文章,有一段時間沒有更新文章了,因為受InfoQ的約稿,梳理了一下子從傳統機器學習時代到深度學習時代所有經典CTR模型的演化關係和模型特點。我們這篇文章先從前深度學習時代開始,幫大家梳理傳統CTR模型的知識體系。
在互聯網永不停歇的增長需求的驅動下,CTR預估模型(以下簡稱CTR模型)的發展也可謂一日千里,從2010年之前千篇一律的邏輯回歸(Logistic Regression,LR),進化到因子分解機(Factorization Machine,FM)、梯度提升樹(Gradient Boosting Decision Tree,GBDT),再到2015年之後深度學習的百花齊放,各種模型架構層出不窮。
我想所有從業者談起深度學習CTR預估模型都有一種莫名的興奮,但在這之前,認真的回顧前深度學習時代的CTR模型仍是非常必要的。原因有兩點:
- 即使是深度學習空前流行的今天, LR、FM等傳統CTR模型仍然憑藉其可解釋性強、輕量級的訓練部署要求、便於在線學習等不可替代的優勢,擁有大量適用的應用場景。模型的應用不分新舊貴賤,熟悉每種模型的優缺點,能夠靈活運用和改進不同的算法模型是算法工程師的基本要求。
- 傳統CTR模型是深度學習CTR模型的基礎。深度神經網絡(Deep Nerual Network,DNN)從一個神經元生髮而來,而LR正是單一神經元的經典結構;此外,影響力很大的FNN,DeepFM,NFM等深度學習模型更是與傳統的FM模型有著千絲萬縷的聯繫;更不要說各種梯度下降方法的一脈相承。所以說傳統CTR模型是深度學習模型的地基和入口。
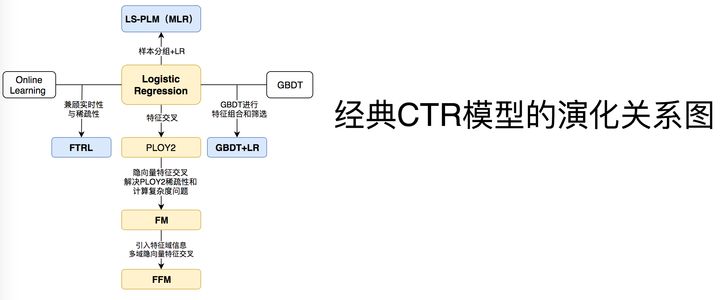
下面,我們用傳統CTR模型演化的關係圖來正式開始技術部分的內容。

看到上面的關係圖,有經驗的同學可能已經對各模型的細節和特點如數家珍了。中間位置的LR模型向四個方向的延伸分別代表了傳統CTR模型演化的四個方向。
- 向下為了解決特徵交叉的問題,演化出PLOY2,FM,FFM等模型;
- 向右為了使用模型化、自動化的手段解決之前特徵工程的難題,Facebook將LR與GBDT進行結合,提出了GBDT+LR組合模型;
- 向左Google從online learning的角度解決模型時效性的問題,提出了FTRL ;
- 向上阿里基於樣本分組的思路增加模型的非線性,提出了LS-PLM(MLR)模型。
一、 LR——CTR模型的核心和基礎
位於正中央的是當之無愧的Logistic Regression。仍記得2012年我剛進入計算廣告這個行業的時候,各大中小公司的主流CTR模型無一例外全都是LR模型。 LR模型的流行是有三方面原因的,一是數學形式和含義上的支撐;二是人類的直覺和可解釋性的原因;三是工程化的需要。
- 邏輯回歸的數學基礎
邏輯回歸作為廣義線性模型的一種,它的假設是因變量y服從伯努利分佈。那麼在點擊率預估這個問題上,“點擊”這個事件是否發生就是模型的因變量y。而用戶是否點擊廣告這個問題是一個經典的擲偏心硬幣問題,因此CTR模型的因變量顯然應該服從伯努利分佈。所以採用LR作為CTR 模型是符合“點擊”這一事件的物理意義的。
與之相比較,線性回歸(Linear Regression)作為廣義線性模型的另一個特例,其假設是因變量y服從高斯分佈,這明顯不是點擊這類二分類問題的數學假設。
在了解LR的數學理論基礎後,其數學形式就不再是空中樓閣了,具體的形式如下:

其中x是輸入向量,θ 是我們要學習的參數向量。結合CTR模型的問題來說,x就是輸入的特徵向量,h(x)就是我們最終希望得到的點擊率。
2.人類的直覺和可解釋性
直觀來講,LR模型目標函數的形式就是各特徵的加權和,再施以sigmoid函數。忽略其數學基礎(雖然這是其模型成立的本質支撐),僅靠人類的直覺認知也可以一定程度上得出使用LR作為CTR模型的合理性。
使用各特徵的加權和是為了綜合不同特徵對CTR的影響,而由於不同特徵的重要程度不一樣,所以為不同特徵指定不同的權重來代表不同特徵的重要程度。最後要套上sigmoid函數,正是希望其值能夠映射到0-1之間,使其符合CTR的物理意義。
LR如此符合人類的直覺認知顯然有其他的好處,就是模型具有極強的可解釋性,算法工程師們可以輕易的解釋哪些特徵比較重要,在CTR模型的預測有偏差的時候,也可以輕易找到哪些因素影響了最後的結果,如果你有跟運營、產品一起工作的經驗的話,更會知道可解釋性強是一個模型多麼優秀的“品質”。
3.工程化的需要
在互聯網公司每天動輒TB級別的數據面前,模型的訓練開銷就異常重要了。在GPU尚未流行開來的2012年之前,LR模型也憑藉其易於並行化、模型簡單、訓練開銷小等特點佔據著工程領域的主流。囿於工程團隊的限制,即使其他復雜模型的效果有所提升,在沒有明顯beat LR之前,公司也不會貿然加大計算資源的投入升級CTR模型,這是LR持續流行的另一重要原因。
二、POLY2——特徵交叉的開始
但LR的表達能力畢竟是非常初級的。由於LR僅使用單一特徵,無法利用高維訊息,在“辛普森悖論”現象的存在下,只用單一特徵進行判斷,甚至會得出錯誤的結論。
針對這個問題,當時的算法工程師們經常採用手動組合特徵,再通過各種分析手段篩選特徵的方法。但這個方法無疑是殘忍的,完全不符合“懶惰是程序員的美德”這一金科玉律。更遺憾的是,人類的經驗往往有局限性,程序員的時間和精力也無法支撐其找到最優的特徵組合。因此採用PLOY2模型進行特徵的“暴力”組合成為了可行的選擇。

在上面POLY2二階部分的目標函數中(上式省略一階部分和sigmoid函數的部分),我們可以看到POLY2對所有特徵進行了兩兩交叉,並對所有的特徵組合賦予了權重 。 POLY2通過暴力組合特徵的方式一定程度上解決了特徵組合的問題。並且由於本質上仍是線性模型,其訓練方法與LR並無區別,便於工程上的兼容。
但POLY2這一模型同時存在著兩個巨大的缺陷:
- 由於在處理互聯網數據時,經常採用one-hot的方法處理id類數據,致使特徵向量極度稀疏,POLY2進行無選擇的特徵交叉使原本就非常稀疏的特徵向量更加稀疏,使得大部分交叉特徵的權重缺乏有效的數據進行訓練,無法收斂。
- 權重參數的數量由n直接上升到n^2,極大增加了訓練複雜度。
三、FM——隱向量特徵交叉
為了解決POLY2模型的缺陷,2010年德國康斯坦茨大學的Steffen Rendle提出了FM(Factorization Machine)。

從FM的目標函數的二階部分中我們可以看到,相比POLY2,主要區別是用兩個向量的內積( wj1 · wj2 )取代了單一的權重 。具體來說,FM為每個特徵學習了一個隱權重向量(latent vector),在特徵交叉時,使用兩個特徵隱向量的內積作為交叉特徵的權重。
通過引入特徵隱向量的方式,直接把原先n^2級別的權重數量減低到了n*k(k為隱向量維度,n>>k)。在訓練過程中,又可以通過轉換目標函數形式的方法,使FM的訓練複雜度進一步降低到n*k級別。相比POLY2極大降低訓練開銷。
隱向量的引入還使得FM比POLY2能夠更好的解決數據稀疏性的問題。舉例來說,我們有兩個特徵,分別是channel和brand,一個訓練樣本的feature組合是(ESPN, Adidas),在POLY2中,只有當ESPN和Adidas同時出現在一個訓練樣本中時,模型才能學到這個組合特徵對應的權重。而在FM中,ESPN的隱向量也可以通過(ESPN, Gucci)這個樣本學到,Adidas的隱向量也可以通過(NBC, Adidas)學到,這大大降低了模型對於數據稀疏性的要求。甚至對於一個從未出現過的特徵組合(NBC, Gucci),由於模型之前已經分別學習過NBC和Gucci的隱向量,FM也具備了計算該特徵組合權重的能力,這是POLY2無法實現的。也許FM相比POLY2丟失了某些訊息的記憶能力,但是泛化能力大大提高,這對於互聯網的數據特點是非常重要的。
工程方面,FM同樣可以用梯度下降進行學習的特點使其不失實時性和靈活性。相比之後深度學習模型複雜的網絡結構,FM比較容易實現的inference過程也使其沒有serving的難題。因此FM在2012-2014年前後逐漸成為業界CTR模型的重要選擇。
四、FFM——引入特徵域概念
2015年,基於FM提出的FFM(Field-aware Factorization Machine ,簡稱FFM)在多項CTR預估大賽中一舉奪魁,並隨後被Criteo、美團等公司深度應用在CTR預估,推薦系統領域。相比FM模型,FFM模型主要引入了Field-aware這一概念,使模型的表達能力更強。

上式是FFM的目標函數的二階部分。其與FM目標函數的區別就在於隱向量由原來的 變成了
,這就意味著每個特徵對應的不是一個隱向量,而是對應著不同域的一組隱向量,當
特徵與
特徵進行交叉時,
特徵會從一組隱向量中挑出與特徵
的域f2對應的隱向量
進行交叉。同理特徵
也會用與
的域f1對應的隱向量進行交叉。
這裡再次強調一下,上面所說的“域”就代表著特徵域,域內的特徵一般會採用one-hot編碼形成one-hot特徵向量。
FFM模型學習每個特徵在f個域上的k維隱向量,交叉特徵的權重由特徵在對方特徵域上的隱向量內積得到,權重數量共n*k*f個。在訓練方面,由於FFM的二次項並不能夠像FM那樣簡化,因此其複雜度為kn^2。
相比FM,FFM由於引入了field這一概念,為模型引入了更多有價值訊息,使模型表達能力更強,但與此同時,FFM的計算複雜度上升到kn^2,遠遠大於FM的k*n。
CTR模型特徵交叉方向的演化
以上模型實際上是CTR模型朝著特徵交叉的方向演化的過程,我們再用圖示方法回顧一下從POLY2到FM,再到FFM進行特徵交叉方法的不同。

POLY2模型直接學習每個交叉特徵的權重,權重數量共n^2個。

FM模型學習每個特徵的k維隱向量,交叉特徵由相應特徵隱向量的內積得到,權重數量共n*k個。

FFM模型引入了特徵域這一概念,在做特徵交叉時,每個特徵選擇與對方域對應的隱向量做內積運算得到交叉特徵的權重。參數數量共n*k*f個。
五、GBDT+LR——特徵工程模型化的開端
FFM模型採用引入特徵域的方式增強了模型的表達能力,但無論如何,FFM只能夠做二階的特徵交叉,如果要繼續提高特徵交叉的維度,不可避免的會發生組合爆炸和計算複雜度過高的情況。那麼有沒有其他的方法可以有效的處理高維特徵組合和篩選的問題? 2014年,Facebook提出了基於GBDT+LR組合模型的解決方案。
簡而言之,Facebook提出了一種利用GBDT自動進行特徵篩选和組合,進而生成新的離散特徵向量,再把該特徵向量當作LR模型輸入,預估CTR的模型結構。

需要強調的是,用GBDT構建特徵工程,和利用LR預估CTR兩步是獨立訓練的。所以自然不存在如何將LR的梯度回傳到GBDT這類複雜的問題,而利用LR預估CTR的過程前面已經有所介紹,在此不再贅述,下面著重講解如何利用GBDT構建新的特徵向量。
大家知道,GBDT是由多棵回歸樹組成的樹林,後一棵樹利用前面樹林的結果與真實結果的殘差做為擬合目標。每棵樹生成的過程是一棵標準的回歸樹生成過程,因此每個節點的分裂是一個自然的特徵選擇的過程,而多層節點的結構自然進行了有效的特徵組合,也就非常高效的解決了過去非常棘手的特徵選擇和特徵組合的問題。
利用訓練集訓練好GBDT模型之後,就可以利用該模型完成從原始特徵向量到新的離散型特徵向量的轉化。具體過程是這樣的,一個訓練樣本在輸入GBDT的某一子樹後,會根據每個節點的規則最終落入某一葉子節點,那麼我們把該葉子節點置為1,其他葉子節點置為0 ,所有葉子節點組成的向量即形成了該棵樹的特徵向量,把GBDT所有子樹的特徵向量連接起來,即形成了後續LR輸入的特徵向量。

舉例來說,如上圖所示,GBDT由三顆子樹構成,每個子樹有4個葉子節點,一個訓練樣本進來後,先後落入“子樹1”的第3個葉節點中,那麼特徵向量就是[0,0,1,0],“子樹2”的第1個葉節點,特徵向量為[1,0,0,0],“子樹3”的第4個葉節點,特徵向量為[0,0,0,1],最後連接所有特徵向量,形成最終的特徵向量[0,0,1,0,1,0,0,0,0,0,0,1]。
由於決策樹的結構特點,事實上,決策樹的深度就決定了特徵交叉的維度。如果決策樹的深度為4,通過三次節點分裂,最終的葉節點實際上是進行了3階特徵組合後的結果,如此強的特徵組合能力顯然是FM系的模型不具備的。但由於GBDT容易產生過擬合,以及GBDT這種特徵轉換方式實際上丟失了大量特徵的數值訊息,因此我們不能簡單說GBDT由於特徵交叉的能力更強,效果就比FFM好,在模型的選擇和調試上,永遠都是多種因素綜合作用的結果。
GBDT+LR比FM重要的意義在於,它大大推進了特徵工程模型化這一重要趨勢,某種意義上來說,之後深度學習的各類網絡結構,以及embedding技術的應用,都是這一趨勢的延續。
在之前所有的模型演化過程中,實際上是從特徵工程這一角度來推演的。接下來,我們從時效性這個角度出發,看一看模型的更新頻率是如何影響模型效果的。

在模型更新這個問題上,我們的直覺是模型的訓練時間和serving時間之間的間隔越短,模型的效果越好,為了證明這一點,facebook的工程師還是做了一組實效性的實驗(如上圖),在結束模型的訓練之後,觀察了其後6天的模型loss(這裡採用normalized entropy作為loss)。可以看出,模型的loss在第0天之後就有所上升,特別是第2天過後顯著上升。因此daily update的模型相比weekly update的模型效果肯定是有大幅提升的。
如果說日更新的模型比周更新的模型的效果提升顯著,我們有沒有方法實時引入模型的效果反饋數據,做到模型的實時更新從而進一步提升CTR模型的效果呢? Google 2013年應用的FTRL給了我們答案。
六、FTRL——天下武功,唯快不破
FTRL的全稱是Follow-the-regularized-Leader,是一種在線實時訓練模型的方法,Google在2010年提出了FTRL的思路,2013年實現了FTRL的工程化,之後快速成為online learning的主流方法。與模型演化圖中的其他模型不同,FTRL本質上是模型的訓練方法。雖然Google的工程化方案是針對LR模型的,但理論上FTRL可以應用在FM,NN等任何通過梯度下降訓練的模型上。
為了更清楚的認識FTRL,這裡對梯度下降方法做一個簡要的介紹,從訓練樣本的規模角度來說,梯度下降可以分為:batch,mini-batch,SGD(隨機梯度下降)三種,batch方法每次都使用全量訓練樣本計算本次迭代的梯度方向,mini-batch使用一小部分樣本進行迭代,而SGD每次只利用一個樣本計算梯度。對於online learning來說,為了進行實時得將最新產生的樣本反饋到模型中,SGD無疑是最合適的訓練方式。
但SGD對於互利網廣告和推薦的場景來說,有比較大的缺陷,就是難以產生稀疏解。為什麼稀疏解對於CTR模型如此重要呢?
之前我們已經多次強調,由於one hot等id類特徵處理方法導致廣告和推薦場景下的樣本特徵向量極度稀疏,維度極高,動輒達到百萬、千萬量級。為了不割裂特徵選擇和模型訓練兩個步驟,如果能夠在保證精度的前提下盡可能多的讓模型的參數權重為0,那麼我們就可以自動過濾掉這些權重為0的特徵,生成一個“輕量級”的模型。 “輕量級”的模型不僅會使樣本部署的成本大大降低,而且可以極大降低模型inference的計算延遲。這就是模型稀疏性的重要之處。
而SGD由於每次迭代只選取一個樣本,梯度下降的方向雖然總體朝向全局最優解,但微觀上的運動的過程呈現布朗運動的形式,這就導致SGD會使幾乎所有特徵的權重非零。即使加入L1正則化項,由於CPU浮點運算的結果很難精確的得到0的結果,也不會完全解決SGD稀疏性差的問題。就是在這樣的前提下,FTRL幾乎完美地解決了模型精度和模型稀疏性兼顧的訓練問題。

但FTRL的提出也並不是一蹴而就的。如上圖所示,FTRL的提出經歷了下面幾個關鍵的過程:
- 從最近簡單的SGD到OGD (online gradient descent),OGD通過引入L1正則化簡單解決稀疏性問題;
- 從OGD到截斷梯度法,通過暴力截斷小數值梯度的方法保證模型的稀疏性,但損失了梯度下降的效率和精度;
- FOBOS (Forward-Backward Splitting),google和伯克利對OGD做進一步改進,09年提出了保證精度並兼顧稀疏性的FOBOS方法;
- RDA :微軟拋棄了梯度下降這條路,獨闢蹊徑提出了正則對偶平均來進行online learning的方法,其特點是稀疏性極佳,但損失了部分精度。
- Google綜合FOBOS在精度上的優勢和RDA在稀疏性上的優勢,將二者的形式進行了進一步統一,提出並應用FTRL,使FOBOS和RDA均成為了FTRL在特定條件下的特殊形式。
FTRL的算法細節對於初學者來說仍然是晦澀的,建議非專業的同學僅了解其特點和應用場景即可。對算法的數學形式和實現細節感興趣的同學,我強烈推薦微博馮揚寫的“在線最優化求解”一文,希望能夠幫助大家進一步熟悉FTRL的技術細節。
七、LS-PLM——阿里曾經的主流CTR模型
下面我們從樣本pattern本身來入手,介紹阿里的的LS-PLM(Large Scale Piece-wise Linear Model),它的另一個更廣為人知的名字是MLR(Mixed Logistic Regression)。 MLR模型雖然在2017年才公之於眾,但其早在2012年就是阿里主流的CTR模型,並且在深度學習模型提出之前長時間應用於阿里的各類廣告場景。
本質上,MLR可以看做是對LR的自然推廣,它在LR的基礎上採用分而治之的思路,先對樣本進行分片,再在樣本分片中應用LR進行CTR預估。在LR的基礎上加入聚類的思想,其動機其實來源於對計算廣告領域樣本特點的觀察。
舉例來說,如果CTR模型要預估的是女性受眾點擊女裝廣告的CTR,顯然我們並不希望把男性用戶點擊數碼類產品的樣本數據也考慮進來,因為這樣的樣本不僅對於女性購買女裝這樣的廣告場景毫無相關性,甚至會在模型訓練過程中擾亂相關特徵的權重。為了讓CTR模型對不同用戶群體,不用用戶場景更有針對性,其實理想的方法是先對全量樣本進行聚類,再對每個分類施以LR模型進行CTR預估。 MLR的實現思路就是由該動機產生的。

MLR目標函數的數學形式如上式,首先用聚類函數π對樣本進行分類(這裡的π採用了softmax函數,對樣本進行多分類),再用LR模型計算樣本在分片中具體的CTR,然後將二者進行相乘後加和。
其中超參數分片數m可以較好地平衡模型的擬合與推廣能力。當m=1時MLR就退化為普通的LR,m越大模型的擬合能力越強,但是模型參數規模隨m線性增長,相應所需的訓練樣本也隨之增長。在實踐中,阿里給出了m的經驗值為12。
下圖中MLR模型用4個分片可以完美地擬合出數據中的菱形分類面。

MLR算法適合於工業級的廣告、推薦等大規模稀疏數據場景問題。主要是由於表達能力強、稀疏性高等兩個優勢:
- 端到端的非線性學習:從模型端自動挖掘數據中蘊藏的非線性模式,省去了大量的人工特徵設計,這使得MLR算法可以端到端地完成訓練,在不同場景中的遷移和應用非常輕鬆。
- 稀疏性:MLR在建模時引入了L1和L2,1範數,可以使得最終訓練出來的模型具有較高的稀疏度,模型的學習和在線預測性能更好。
如果我們用深度學習的眼光來看待MLR這個模型,其在結構上已經很接近由輸入層、單隱層、輸出層組成的神經網絡。所以某種意義上說,MLR也在用自己的方式逐漸逼近深度學習的大門了。
深度學習CTR模型的前夜
2010年FM被提出,特徵交叉的概念被引入CTR模型;2012年MLR在阿里大規模應用,其結構十分接近三層神經網絡;2014年Facebook用GBDT處理特徵,揭開了特徵工程模型化的篇章。這些概念都將在深度學習CTR模型中繼續應用,持續發光。
另一邊,Alex Krizhevsky 2012年提出了引爆整個深度學習浪潮的AlexNet,深度學習的大幕正式拉開,其應用逐漸從圖像擴展到語音,再到NLP領域,推薦和廣告也必然會緊隨其後,投入深度學習的大潮之中。
2016年,隨著FNN,Deep&Wide,Deep crossing等一大批優秀的CTR模型框架的提出,深度學習CTR模型逐漸席捲了推薦和廣告領域,成為新一代CTR模型當之無愧的主流。下一篇文章,我們將繼續探討深度學習CTR模型,從模型演化的角度揭開所有主流深度學習CTR模型之間的關係和每個模型的特點,期待繼續與你一同學習討論。

最後再次強調一下模型的演化圖,希望大家能從更高的角度審視整個CTR模型的發展過程。
這裡是「王喆的機器學習筆記」 ,因為文章的內容較多,水平有限,希望大家能夠踴躍指出文章中的錯誤,先多謝大家!也歡迎大家關注我的微信公眾號王喆的機器學習筆記( wangzhenotes ),跟踪計算廣告、推薦系統等機器學習領域前沿,謝謝!
參考資料:
- [LR] Predicting Clicks - Estimating the Click-Through Rate for New Ads (Microsoft 2007)
- [FFM] Field-aware Factorization Machines for CTR Prediction (Criteo 2016)
- [GBDT+LR] Practical Lessons from Predicting Clicks on Ads at Facebook (Facebook 2014)
- [PS-PLM] Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction (Alibaba 2017)
- [FTRL] Ad Click Prediction a View from the Trenches (Google 2013)
- [FM] Fast Context-aware Recommendations with Factorization Machines (UKON 2011)
本文亦收錄在我的新書「 深度學習推薦系統」中,這本書系統性地整理、介紹了專欄中所有的重點內容,如果您曾在「王喆的機器學習筆記」中受益,歡迎訂閱,謝謝知友們的支持!
